1. 자료구조
Array & Linked List
Q. Array는 어떤 자료구조 인가요?
[핵심 답변]
Array는 연관된 data를 메모리상에 연속적이며 순차적으로 미리 할당된 크기만큼 저장하는 자료구조 입니다.
[면접
💡 Array에 관한 질문을 할 때에는 매우 높은 확률로 Linked List에 대한 질문도 나오게 됩니다. 따라서 Array의 다양한 특징 중에서 Linked List와 비교가 되는 특성들을 위주로 대답을 하게 되면 편하게 풀어나갈 수 있습니다!
Array와 Linked List의 가장 큰 차이점은 메모리에 저장되는 방식과 이에 따른 operation의 연산 속도(time complexity) 입니다. 이를 유념해서 공부해 가시면 좋은 답변을 하실 수 있습니다.
Array의 특징
- 고정된 저장 공간(fixed-size)
- 순차적인 데이터 저장(order)
Array의 장점은 lookup과 append가 빠르다는 것입니다. 따라서 조회를 자주 해야되는 작업에서는 Array 자료구조를 많이 씁니다.
Array의 단점은 fixed-size 특성상 선언시에 Array의 크기를 미리 정해야 된다는 것입니다. 이는 메모리 낭비나 추가적인 overhead가 발생할 수 있습니다.
시간복잡도
| Array | |
|---|---|
| access | |
| append | |
| 마지막 원소delete | |
| insertion | |
| deletion | |
| search |
[꼬꼬무 문답]
Q) 미리 예상한 것보다 더 많은 수의 data를 저장하느라 Array의 size를 넘어서게 됐습니다. 이 때, 어떻게 해결할 수 있을까요?
**[핵심 답변]**
기존의 size보다 더 큰 Array를 선언하여 데이터를 옮겨 할당합니다. 모든 데이터를 옮겼다면 기존 Array는 메모리에서 삭제하면 됩니다. 이런식으로 동적으로 배열의 크기를 조절하는 자료구조를 Dynamic array라고 합니다.
또 다른 방법으로는, size를 예측하기 쉽지 않다면 Array대신 Linked list를 사용함으로써 데이터가 추가될 때마다 메모리공간을 할당받는 방식을 사용하면 됩니다.
Q. Dynamic Array는 어떤 자료구조 인가요?
[핵심 답변]
Array의 경우 size가 고정되었기 때문에 선언시에 설정한 size보다 많은 갯수의 data가 추가되면 저장할 수 없습니다. 이에 반해 Dynamic Array는 저장공간이 가득 차게 되면 resize를 하여 유동적으로 size를 조절하여 데이터를 저장하는 자료구조 입니다.
[면접
💡 Array의 특징중에 fixed-size의 한계점을 보완하고자 고안된 자료구조인 Dynamic Array에 대해서 면접을 위해 깊게 공부하실 내용은 크게 두 가지 입니다.
- resize를 하는 방식
- 데이터 추가(append)할 때의 시간복잡도
Dynamic Array

Dynamic Array는 size를 자동적으로 resizing을 하는 Array입니다. 기존에 고정된 size를 가진 Static Array의 한계점을 보안하고자 고안되었습니다. Dynamic Array는 data를 계속 추가하다가 기존에 할당된 memory를 초과하게 되면, size를 늘린 배열을 선언하고 그곳으로 모든 데이터를 옮김으로써 늘어난 크기의 size를 가진 배열이 됩니다. 이를 resize라고 합니다. 이로써 새로운 data를 저장할 수 있게 됩니다. 따라서 Dynamic Array는 size를 미리 고민할 필요없다는 장점이 있습니다.
resizing 을 하는 방법은 여러 가지가 있는데, 대표적으로 기존 Array size의 2배 size를 할당하는 doubling이 있습니다.
Doubling
resize의 대표적인 방법으로는 Doubling이 있습니다. 데이터를 추가(append

분할상환 시간복잡도 Amortized time complexity
Dynamic array에 데이터를 추가할 때마다
그렇다면 결과적으로 append의 시간복잡도는
append의 총 과정을 살펴보면 데이터를 마지막 인덱스에 추가하는(
쉽게 설명하자면 가끔 발생하는 O(n)의 resize하는 시간을, 자주 발생하는 O(1)의 작업들이 분담해서 나눠 가짐으로써 전체적으로 O(1)의 시간이 걸린다고 생각하시면 됩니다.
[꼬꼬무 문답]
Q) Dynamic Array를 Linked list와 비교하여 장단점을 설명해 주세요.
**[핵심 답변]**
Linked List와 비교했을 때, Dynamic Array의 장점은
- 데이터 접근과 할당이 $O(1)$로 굉장히 빠릅니다. 이는 index 접근하는 방법이 산술적인 연산 [배열 첫 data의 주소값] + [offset]으로 이루어져 있긴 때문입니다. (randam access)
- Dynamic Array의 맨 뒤에 데이터를 추가하거나 삭제하는 것이 상대적으로 빠릅니다.($O(1)$)
Linked List와 비교했을 때, Dynamic Array의 단점은
- Dynamic Array의 맨 끝이 아닌 곳에 data를 insert or remove할 때, 느린 편입니다($O(n)$). 느린 이유는 메모리상에서 연속적으로 데이터들이 저장되어 있기 때문에, 데이터를 추가 삭제할 때 뒤에 있는 data들을 모두 한칸씩 shift 해야되기 때문입니다.
- resize를 해야할 때, 예상치 못하게 현저히 낮은 performance가 발생합니다.
- resize에 시간이 많이 걸리므로 필요한 것 이상 memory공간을 할당받습니다. 따라서 사용하지 않고 있는 낭비되는 메모리공간이 발생합니다.
Q. Linked List에 대해서 설명해 주세요.
[핵심 답변]
Linked List는 Node라는 구조체로 이루어져 있는데, Node는 데이터 값과 다음 Node의 address를 저장합니다. Linked List는 물리적인 메모리상에서는 비연속적으로 저장이 되지만 Linked list를 구성하는 각각의 Node가 next Node의 address를 가리킴으로써 논리적인 연속성을 가진 자료구조입니다.
[면접
💡 Linked List는 tree, graph등 다른 자료구조를 구현할 때 자주 쓰이는 기본 자료구조 입니다. 면접에서 Linked list를 설명할 때에는 메모리상에서 불연속적으로 데이터가 저장되는 점과 Node의 next address를 통해 불연속적인 데이터를 연결하여 논리적 연속성을 보장한다는 점을 중심으로 설명하면 됩니다.
또한, 데이터가 추가 되는 시점에서 메모리를 할당하기 때문에 메모리를 좀 더 효율적으로 사용할 수 있다는 장점도 답변으로 구성하면 좋습니다.
물리적 메모리 관점에서 본 Linked list - 비연속적
논리적 연속성
각 Node들은 next address정보를 가지고 있기 때문에 논리적으로 연속성을 유지하면서 연결되어 있습니다. Array의 경우 연속성을 유지하기 위해 물리적 메모리 상에서 순차적으로 저장하는 방법을 사용하였고, Linked list에는 메모리에서 연속성을 유지하지 않아도 되기 때문에 메모리 사용이 좀 더 자유로운 대신, Next address를 추가적으로 저장해야 하기 때문에 데이터 하나당 차지하는 메모리가 더 커지게 됩니다.
(1) 그림에서 링크드리스트가 연속적으로 저장된것처럼 보이지만 실제 메모리상에서는 (2)와 같다
(1) 논리적 연속성

(2) 물리적 불연속성

시간복잡도
Array의 경우 중간에 데이터를 삽입/삭제하게 되면 해당 인덱스의 뒤에 있는 모든 원소들은 shift를 해야만 했습니다. 그러다 보니
| Linked list | |
|---|---|
| access | |
| search | |
| insertion | |
| deletion |


Q. ⭐ Array vs Linked list를 비교해서 설명해주세요
[핵심 답변]
Array는 메모리 상에서 연속적으로 데이터를 저장하는 자료구조 입니다. Linked List는 메모리상에서는 연속적이지 않지만, 각각의 원소가 다음 원소의 메모리 주소값을 저장해 놓음으로써 논리적 연속성을 유지합니다.
그래서 각 operation의 시간복잡도가 다릅니다. 데이터 조회는 Array의 경우
따라서 얼마만큼의 데이터를 저장할지 미리 알고있고, 조회를 많이 한다면 Array를 사용하는 것이 좋습니다. 반면에 몇개의 데이터를 저장할 지 불확실하고 삽입 삭제가 잦다면 Linked list를 사용하는 것이 유리합니다.
[면접
💡 Array와 Linked List의 주된 차이점들은 메모리 구조에 기인합니다. Array는 메모리상에서 연속적으로 데이터를 저장하고, Linked List는 불연속적으로 저장합니다. 메모리 구조의 차이로 인해 operation구현방법이 다르고 시간복잡도도 다릅니다. 또한 메모리 활용도에서도 차이가 있습니다. 상황에 따라 메모리를 효율적으로 사용할 수 있는 자료구조가 달라집니다. 이를 유념해서 학습을 해봅시다!
조회 (lookup)
Array는 메모리상에서 연속적으로 데이터를 저장하였기 때문에 저장된 데이터에 즉시 접근(random access
삽입/삭제 (insert/delete)
Array의 경우 맨 마지막 원소를 추가/삭제하면 시간복잡도가
Linked List는 어느 원소를 추가/삭제 하더라도 node에서 다음주소를 가르키는 부분만 다른 주소 값으로 변경하면 되기 때문에 shift할 필요 없어 시간복잡도가
하지만 Linked list의 경우 추가/삭제를 하려는 index까지 도달하는데
memory
Array의 주된 장점은 데이터 접근과 append가 빠르다는 것입니다. 하지만 메모리 낭비라는 단점이 있습니다. 배열은 선언시에 fixed size를 설정하여 메모리 할당을 합니다. 즉, 데이터가 저장되어 있지 않더라도 메모리를 차지하고 있기 때문에 메모리 낭비가 발생합니다.
이와 반면 Linked List는 runtime중에서도 size를 늘리고 줄일 수 있습니다. 그래서 initial size를 고민할 필요 없고, 필요한 만큼 memorry allocation을 하여 메모리 낭비가 없습니다.
[꼬꼬무 문답]
Q. 어느 상황에 Linked list를 쓰는게 Array보다 더 나을까요?
**[핵심 답변]**
- $O(1)$으로 삽입/삭제를 자주 해야 될 때
- 얼마만큼의 데이터가 들어올지 예측을 할 수 없을 때
- 조회 작업을 별로 하지 않을 때
Q. 어느 상황에 Array를 쓰는게 Linked list보다 더 나을까요?
**[핵심 답변]**
- 조회 작업을 자주 해야될 때
- Array를 선언할 당시에 데이터의 갯수를 미리 알고 있을때
- 데이터를 반복문을 통해서 빠르게 순회할 때.
- 메모리를 적게 쓰는게 중요한 상황일 때. Linked list보단 Array가 메모리를 적게 차지 하기 때문에 미리 들어올 데이터의 양을 알고만 있다면 Array가 메모리를 더 효율적으로 사용합니다.
Q. Array와 Linked List의 memory allocation은 언제 일어나며, 메모리의 어느 영역을 할당 받나요?
**[핵심 답변]**
Array는 compile 단계에서 memory allocation이 일어납니다. 이를 Static Memory Allocation이라고 합니다. 이 경우 Stack memory영역에 할당됩니다.
Linked List의 경우 runtime 단계에서 새로운 node가 추가될 때마다 memory allocation이 일어납니다. 이를 Dynamic Memory Allocation이라고 부릅니다. Heap메모리 영역에 할당됩니다.

Queue & Stack
Q. Queue는 무슨 자료구조 인가요?
[핵심 답변]
queue는 선입선출 FIFO(First In First Out)의 자료구조입니다. 시간복잡도는 enqueue
[면접
💡 기초적인 자료구조로 면접에서 간단한 질문으로 종종 나오는 문제입니다. LIFO인 stack과 다르게 FIFO자료구조임을 잘 기억하시고 계시면 됩니다. 또한 활용 예시들과 Circular Queue 자료구조를 잘 알고 계시면 면접에서 충분한 답을 하실 수 있습니다.
FIFO
queue는 시간 순서상 먼저 집어 넣은 데이터가 먼저 나오는 선입선출 FIFO(First In First Out)형식으로 데이터를 저장하는 자료구조입니다.

enqueue & dequeue
queue에서 데이터를 추가하는 것을 enqueue라고 합니다.
queue에서 데이터를 추출 하는 것은 dequeue라고 합니다.
enqueue의 경우 queue의 맨 뒤에 데이터를 추가하면 완료되기 때문에 시간복잡도는 O(1) 입니다. 이와 비슷하게 dequeue의 경우 맨 앞의 데이터를 삭제하면 완료 되기 때문에 동일하게 O(1)의 시간복잡도를 갖습니다.
구현 방식

- Array-Based queue: enqueue와 dequeue 과정에서 남는 메모리가 생깁니다. 따라서 메모리의 낭비를 줄이기 위해 주로 Circular queue형식으로 구현을 합니다.
- List-Based: 재할당이나 메모리 낭비의 걱정을 할 필요가 없어집니다.
원형큐(circular queue)
확장 & 활용
queue의 개념에서 조금 확장한 자료구조들로는 양쪽에서 enqueue와 dequeue가 가능한 deque(double-ended queue)와 시간순서가 아닌 우선순위가 높은 순서로 dequeue할 수 있는 priority queue가 있습니다.
활용 예시로는 하나의 자원을 공유하는 프린터나, CPU task scheduling, Cache구현, 너비우선탐색(BFS) 등이있습니다.
[꼬꼬무 문답]
Q. Array-Base 와 List-Base의 경우 어떤 차이가 있나요?
**[핵심 답변]**
Array-Base의 경우 queue는 circular queue로 구현하는 것이 일반적입니다. 이는 메모리를 효율적으로 사용하기 위함입니다. 또한, enqueue가 계속 발생하면 fixed size를 넘어서게 되기 때문에, dynamic array와 같은 방법으로 Array의 size를 확장시켜야 합니다. 그럼에도 enqueue의 시간복잡도는 (amortized)O(1)를 유지할 수 있습니다.
List-Bases의 경우 보통 singly-lilnked list로 구현을 합니다. enqueue는 단순히 singly-lilnked list에서 append를 하는 것으로 구현되고, 이 때 시간복잡도는 O(1)입니다. dequeue는 맨 앞의 원소를 삭제하고 first head를 변경하면 되기 때문에 이 연산도 O(1)의 시간이 걸립니다.
요약하자면, 두 가지 종류의 자료구조로 queue를 구현을 하더라도 enqueue와 dequeue는 모두 O(1)의 시간복잡도를 갖습니다. Array-Base의 경우 전반적으로 performance가 더 좋지만, worst case의 경우에는 훨씬 더 느릴 수 있습니다(resize). List-Base의 경우에는 enqueue를 할 때마다 memory allocation을 해야 하기 때문에 전반적인 runtime이 느릴 수 있습니다.
Q. Stack은 어떤 자료구조 인가요?
[핵심 답변]
stack은 후입선출 LIFO(Last In First Out)의 자료구조입니다. 시간복잡도는 push
[면접
💡 코딩테스트에서는 stack이 굉장히 중요한 자료구조이지만, 면접에서는 stack을 단독으로 질문하는 경우는 많이 없습니다. 따라서 Queue의 FIFO와 대조되는 LIFO라는 특성과, 활용예시 정도의 기본적인 내용만 이해하고 가시면 충분합니다.
LIFO
stack은 시간 순서상 가장 최근에 추가한 데이터가 가장 먼저 나오는 후입선출 LIFO(Last In First Out)형식으로 데이터를 저장하는 자료구조입니다.

push & pop
stack에서 데이터를 추가하는 것을 push라고 하고 데이터를 추출 하는 것은 pop이라고 합니다. push의 경우 stack의 맨 뒤에 데이터를 추가하면 완료되기 때문에 시간복잡도는 O(1)입니다. 이와 동일하게 pop의 경우도 맨 뒤의 데이터를 삭제하면 완료 되기 때문에 O(1)의 시간복잡도를 갖습니다. push와 pop은 모두 stack의 top에 원소를 추가하거나 삭제하는 형식으로 구현됩니다.
활용
stack은 재귀적인 특징이 있어서 프로그램을 개발할 때 자주 쓰이는 자료구조입니다. 활용 예시로는 call stack, 후위 표기법 연산, 괄호 유효성 검사, 웹 브라우저 방문기록(뒤로 가기), 깊이우선탐색(DFS) 등이 있습니다.
Q. Stack 두 개를 이용하여 Queue를 구현해 보세요
[면접
💡 어디서도 배운적은 없지만 의외로 가끔 나와서 당황했던 면접 질문입니다. 따로 준비해 가지 않으면 현장에서 바로 떠올리기 힘들 수 있지만, 한 번만 준비했다면 쉽게 답할 수 있습니다. stack 두 개를 사용하여 enqueue와 dequeue를 구현하는 것에 초점을 맞춰서 문제를 해결하면 됩니다.
사실 이런 문제는 답이 다양하고, 답 자체가 중요하기 보단 답을 찾아가는 과정을 더 중요하게 보기 때문에, 풀이를 외우기보단 접근 방식을 주의깊게 보시길 바랍니다.
[핵심 답변]
queue의 enqueue()를 구현할 때 첫 번째 stack을 사용하고, dequeue()를 구현할 때 두 번째 stack을 사용하면 queue를 구현할 수 있습니다.
편의상 enqueue()에 사용할 stack을 instack이라고 부르고 dequeue()에 사용할 stack을 outstack이라고 칭하겠습니다. 두 개의 stack으로 queue를 구현하는 방법은 다음과 같습니다.
- enqueue() :: instack에 push()를 하여 데이터를 저장합니다.
- dequeue() ::
- 만약 outstack이 비어 있다면 instack.pop() 을 하고 outstack.push()를 하여 instack에서 outstack으로 모든 데이터를 옮겨 넣습니다. 이 결과로 가장 먼저 왔던 데이터는 outstack의 top에 위치하게 된다.
- outstack.pop()을 하면 가장먼저 왔던 데이터가 가정 먼저 추출된다.(FIFO)
[코드 작성]
class Queue(object):
def __init__(self):
self.instack=[]
self.outstack=[]
def enqueue(self,element):
self.instack.append(element)
def dequeue(self):
if not self.outstack:
while self.instack:
self.outstack.append(self.instack.pop())
return self.outstack.pop()
[꼬꼬무 문답]
Q. 시간복잡도는 어떻게 되는지 설명해 주세요.
**[핵심 답변]**
- enqueue() : instack.push()를 한번만 하면 되기 때문에 시간복잡도 O(1)입니다.
- dequeue() : 두 가지 경우를 따져봐야 합니다. worst case는 outstack이 비어있는 경우입니다. 이 때는 instack에 있는 n개의 데이터를 instack.pop()을 한 이후에 outstack.push()를 해줘야 합니다. 따라서 총 2*n 번의 operation이 실행되어야 하므로 O(n)의 시간복잡도를 갖습니다.
하지만 outstack이 비어있지 않는 경우에는 outstack.pop()만 해주면 됩니다. 이는 O(1)의 시간복잡도를 갖습니다. 이를 종합했을 때, amortized O(1)의 시간복잡도를 갖는다고 할 수 있습니다.
enqueue() - O(1)
dequeue() - O(1)
Q. Queue 두 개를 이용하여 Stack을 구현해 보세요
[면접
💡 queue 두 개를 사용하여 stack의 push와 pop를 구현하는 것에 초점을 맞춰서 문제를 해결하면 됩니다. 구현 방법을 외우기보단 문제를 해결해 나가는 과정을 보여주는 것이 좋습니다.
[핵심 답변]
편의상 push()에 사용할 queue는 q1이라고 부르고 pop()에 사용할 queue를 q2라고 칭하겠습니다. 두 개의 queue로 stack을 구현하는 방법은 다음과 같습니다.
- push() :: q1으로 enqueue()를 하여 데이터를 저장합니다.
- pop() ::
- q1에 저장된 데이터의 갯수가 1 이하로 남을 때까지 dequeue()를 한 후, 추출된 데이터를 q2에 enqueue()합니다. 결과적으로 가장 최근에 들어온 데이터를 제외한 모든 데이터는 q2로 옮겨진다.
- q1에 남아 있는 하나의 데이터를 dequeue()해서 가장 최근에 저장된 데이터를 반환한다.(LIFO)
- 다음에 진행될 pop()을 위와 같은 알고리즘으로 진행하기 위해 q1과 q2의 이름을 swap한다.
[코드 작성]
import queue
class Stack(object):
def __init__(self):
self.q1 = queue.Queue()
self.q2 = queue.Queue()
def push(self, element):
self.q1.put(element)
def pop(self):
while self.q1.qsize() > 1:
self.q2.put(self.q1.get())
temp = self.q1
self.q1 = self.q2
self.q2 = temp
return self.q2.get()
[꼬꼬무 문답]
Q. 시간복잡도는 어떻게 되는지 설명해 주세요.
**[핵심 답변]**
- push() : q1.enqueue()를 한번만 하면 되기 때문에 $O(1)$의 시간복잡도를 갖습니다.
- pop() : q1에 저장되어 있는 n개의 원소중에 n-1개를 q2로 옮겨야 하므로 $O(n)$이 됩니다.
Q. ⭐ Queue vs priority queue를 비교하여 설명해 주세요
[핵심 답변]
Queue 자료구조는 시간 순서상 먼저 집어 넣은 데이터가 먼저 나오는 선입선출 FIFO(First In First Out) 구조로 저장하는 형식입니다. 이와 다르게 우선순위큐(priority queue)는 들어간 순서에 상관없이 우선순위가 높은 데이터가 먼저 나옵니다.
Queue의 operation 시간복잡도는 enqueue dequeue
Priority queue는 push pop
[면접
💡 면접질문에서 우선순위큐를 잘 답하기 위해서는 구현 방법과 operation의 시간복잡도를 잘 설명할 수 있어야 합니다.
우선순위큐를 구현하라고 하면 Heap을 구현하시면 됩니다. Heap 자료구조는 이진완전트리를 활용하는 것이고, 대표적인 operation의 시간복잡도는push, pop입니다. 이 두 가지 특징을 중심으로 공부해 가시면 충분히 답변할 수 있습니다.
또한 tree가 그려져 있는 상태에서 최대힙, 최소힙의 삽입과 삭제시에 어떻게 node가 삭제되고 연결이 변경되는지의 과정을 그려서 설명할 수 있다면 더 좋습니다.
Heap
Heap은 그 자체로 우선순위큐(priority queue)의 구현과 일치합니다.
Heap은 완전이진트리 구조입니다. Heap이 되기 위한 조건은 다음과 같습니다.
-
각 node에 저장된 값은 child node들에 저장된 값보다 작거나 같다(min heap)
⇒ root node에 저장된 값이 가장 작은 값이 된다.


Heap구현
트리는 보통 Linked list로 구현합니다. 하지만 Heap은 tree임에도 불구하고 array를 기반으로 구현해야 합니다. 그 이유는 새로운 node를 힙의 ‘마지막 위치’에 추가해야 하는데, 이 때 array기반으로 구현해야 이 과정이 수월해지기 때문입니다.
- 구현의 편의를 위해 array의 0번 째 index는 사용하지 않습니다.
- 완전이진트리의 특성을 활용하여 array의 index만으로 부모 자식간의 관계를 정의합니다.
번 째 node의 left child node = 번 째 node의 right child node = 번 째 node의 parent node =

Heap push -
heap tree의 높이는
push() 를 했을 때, swap하는 과정이 최대
Heap pop -
pop()을 했을 때, swap하는 과정이 최대
-
각 node에 저장된 값은 child node들에 저장된 값보다 크거나 같다(max heap)
⇒ root node에 저장된 값이 가장 큰 값이 된다.
Hash table & BST(Binary Search Tree)
Q. ⭐⭐BST는 어떤 자료구조 인가요?
[핵심 답변]
이진탐색트리(Binary Search Tree; BST)는 정렬된 tree입니다. 어느 node를 선택하든 해당 node의 left subtree에는 그 node의 값보다 작은 값들을 지닌 node들로만 이루어져 있고, node의 right subtree에는 그 node의 값보다 큰 값들을 지닌 node들로만 이루어져 있는 binary tree입니다.
검색과 저장, 삭제의 시간복잡도는 모두
[ 면접
💡 BST는 저장과 동시에 정렬을 하는 자료구조입니다. 따라서 새로운 데이터를 저장할 때 일정한 규칙에 따라 저장을 하게 됩니다. Heap을 공부했었을 때와 마찬가지로, 저장하는 방식을 그림으로 설명할 수 있으면 좋습니다.
이진탐색트리가 되기 위한 조건이 무엇인지, 시간복잡도, worst case, worst case가 발생하지 않게 하기 위해서는 어떻게 해야하는지를 대답할 수 있으면 됩니다.
BST는 자주 나오면서 꽤 어려운 자료구조이기 때문에 충분한 학습을 하고 면접을 보러 가시길 바랍니다.
BST


BST 조건
- root node의 값보다 작은 값은 left subtree에, 큰 값은 right subtree에 있다.
- subtree도 1번 조건을 만족한다.(Recursive)


search




[꼬꼬무 문답]
Q. 이진트리(Binary tree)는 어떤 자료구조 인가요?
**[핵심 답변]**
모든 node의 child nodes의 갯수가 2 이하인 트리를 이진 트리라고 합니다.
Q. BST의 worst case 시간복잡도는
**[핵심 답변]**
균형이 많이 깨져서 한 쪽으로 치우친 BST의 경우에 worst case가 됩니다. 이렇게 되면 Linked list와 다를게 없어집니다. 따라서 탐색시에 $O(logn)$이 아니라 $O(n)$이 됩니다.

Q. 해결방법은 무엇인가요
**[핵심 답변]**
자가 균형 이진 탐색 트리(Self-Balancing BST)는 알고리즘으로 이진 트리의 균형이 잘 맞도록 유지하여 높이를 가능한 낮게 유지합니다. 대표적으로 AVL트리와 Red-black tree가 있습니다. JAVA에서는 hashmap의 seperate chaning으로써 Linked list와 Red-black tree를 병행하여 저장합니다.
Q. ⭐⭐ Hash table는 어떤 자료구조 인가요?
[핵심 답변]
hash table은 효율적인 탐색(빠른 탐색)을 위한 자료구조로써 key-value쌍의 데이터를 입력받습니다. hash function
[면접
💡 cs 면접에서 가장 자주 나오는 질문중에 하나입니다. hashtable이 면접 단골질문인 이유는 다음과 같습니다.
- 실무에서도 활용도가 높은 자료구조입니다.
- Linked list, Array 더 나아가면 Tree까지 질문할 수 있습니다.
- 시간복잡도에 대해서 물어보기 좋습니다.
한편, 좋은 hash function의 조건을 물어보는 경우도 있습니다. 좋은 hash function의 핵심적인 조건은 해시값이 고르게 분포되게 하는 것입니다.
Direct-address Table
Direct-address Table(직접 주소화 테이블)이란, key 값으로 k를 갖는 원소는 index k에 저장하는 방식입니다.
key: 출석번호, value: 이름
(3, 노정호)
(5, 배준석)
(6, 정재헌)
(7, 남영욱)

직접 주소화 방법으로 통해 key-value 쌍의 데이터를 저장하고자 하면 많은 문제가 발생합니다.
- 불필요한 공간 낭비
key: 학번, value: 이름
(2022390, 노정호)
(2022392, 배준석)
(2022393, 정재헌)
(2022401, 남영욱)

- key가 다양한 자료형을 담을 수 없게 됨
key: ID, value: 이름
(nossi8128, 노정호)
(js9876, 배준석)
(zebra001, 정재헌)
(nam1234, 남영욱)

Hash table
(key, value) 데이터 쌍을 저장하기 위한 방법으로 직접 주소화 방법이 잘 맞지않습니다. hash table은 hash function
한편, hash table을 구성하고 있는, (key, value)데이터를 저장할 수 있는 각각의 공간을 slot 또는 bucket이라고 합니다.


Collision
collision이란 서로 다른 key의 해시값이 똑같을 때를 말합니다. 즉, 중복되는 key는 없지만 해시값은 중복될 수 있는데 이 때 collision이 발생했다고 합니다. 따라서 collision이 최대한 적게 나도록 hash function을 잘 설계해야하고, 어쩔 수 없이 collision이 발생하는 경우 seperate chaining 또는 open addressing등의 방법을 사용하여 해결합니다.

시간복잡도와 공간효율
시간복잡도는 저장, 삭제, 검색 모두 기본적으로
공간효율성은 떨어집니다. 데이터가 저장되기 전에 미리 저장공간(slot, bucket)을 확보해야 하기 때문입니다. 따라서 저장공간이 부족하거나 채워지지 않은 부분이 많은 경우가 생길 수 있습니다.
[꼬꼬무 문답]
Q. 좋은 hash function의 조건은 뭘까요?
**[핵심 답변]**
각 상황마다 good hash function은 달라질 수 있으나 대략적인 기준은 연산 속도가 빨라야 하고, 해시값이 최대한 겹치지 않아야 합니다.
Q. ⭐⭐⭐⭐ Hash table에서 collision이 발생하면 어떻게 되나요? 해결방법엔 뭐가 있을까요?
[핵심 답변]
collision이 발생할 경우 대표적으로 2가지 방법으로 해결합니다.
첫 번째, open addressing 방식은 collision이 발생하면 미리 정한 규칙에 따라 hash table의 비어있는 slot을 찾습니다. 빈 slot을 찾는 방법에 따라 크게 Linear Probing, Quadratic Probing, Double Hashing으로 나뉩니다.
두 번째, separete chaining 방식은 linked list를 이용합니다. 만약에 collision이 발생하면 linked list에 노드(slot)를 추가하여 데이터를 저장합니다.
[면접
💡 정말 자주나오고 중요한 면접 질문입니다. 꼭 철저하게 준비해가시길 추천드립니다. hashtable에서 collision이 발생했을 때, seperate chaining과 open addressing 두 가지 방식으로 해결을 합니다. 두 가지 방법이 어떤 메커니즘으로 작동하는지, 어떤 차이점이 있는지를 잘 학습하고 가시기 바랍니다.
또한 seperate chaining의 경우 worst case의 시간복잡도에 대해서 설명할 줄 알아야 합니다. 삽입과 검색, 삭제의 시간복잡도는이지만, worst case의 경우에 가 될 수 있습니다. 왜 이 되는지를 설명할 수 있도록 collision에 대해서 같이 살펴보도록 할게요!
Open addressing
open addressing 방식은 collision이 발생하면 미리 정한 규칙에 따라 hash table의 비어있는 slot을 찾습니다. 추가적인 메모리를 사용하지 않으므로 linked list 또는 tree자료구조를 통해 추가로 메모리 할당을 하는 separate chaining방식에 비해 메모리를 적게 사용합니다.
open addressing은 빈 slot을 찾는 방법에 따라 크게 Linear Probing, Quadratic Probing, Double Hashing으로 나뉩니다.
-
Linear Probing(선형 조사법)& Quadratic Probing(이차 조사법) : 선형 조사법은 충돌이 발생한 해시값으로 부터 일정한 값만큼
건너 뛰어, 비어 있는 slot에 데이터를 저장합니다. 이차 조사법은 제곱수( )로 건너 뛰어, 비어 있는 slot을 찾습니다. 충돌이 여러번 발생하면 여러번 건너 뛰어 빈 slot을 찾습니다. 선형 조사법과 이차 조사법의 경우 충돌 횟수가 많아지면 특정 영역에 데이터가 집중적으로 몰리는 클러스터링(clustering)현상이 발생하는 단점이 있습니다. 클러스터링 현상이 발생하면, 평균 탐색 시간이 증가하게 됩니다.
-
Double Hashing(이중해시, 중복해시) : 이중 해싱은 open addressing 방식을 통해 collision을 해결할 때, probing하는 방식중에 하나입니다. linear probing이나 quadratic probing을 통해 탐사할 때는 탐사이동폭이 같기 때문에 클러스터링 문제가 발생할 수 있습니다. 클러스터링 문제가 발생하지 않도록 2개의 해시함수를 사용하는 방식을 이중 해싱이라고 합니다. 하나는 최초의 해시값을 얻을 때 사용하고 또 다른 하나는 해시 충돌이 발생할 때 탐사 이동폭을 얻기 위해 사용합니다.
Separate chaining
Separate chaining 방식은 linked list(또는 Tree)를 이용하여 collision을 해결합니다. 충돌이 발생하면 linked list에 노드(slot)를 추가하여 데이터를 저장합니다.
- 삽입: 서로 다른 두 key가 같은 해시값을 갖게 되면 linked list에 node를 추가하여 (key, value) 데이터 쌍을 저장합니다. 삽입의 시간복잡도는
입니다. - 검색: 기본적으로
의 시간복잡도 이지만 최악의 경우 의 시간복잡도를 갖습니다. - 삭제: 삭제를 하기 위해선 검색을 먼저 해야하므로 검색의 시간복잡도와 동일합니다. 기본적으로
이지만 최악의 경우 의 시간복잡도를 갖습니다.
worst case의 경우 n개의 모든 key가 동일한 해시값을 갖게 되면 길이 n의 linked list가 생성되게 됩니다. 이 때, 검색의 시간복잡도가

⁉️참고: seperate chaining은 기본적으로 linked list를 이용하여 데이터를 저장하지만, collision이 많이 발생하여 linked list의 길이가 길어지면 Binary Search Tree(BST)자료구조를 이용하여 데이터를 저장하기도 합니다. BST를 사용함으로써 검색의 worst case 시간복잡도를
[꼬꼬무 문답]
Q. worst case에 시간복잡도는
**[핵심 답변]**
n개의 모든 key가 동일한 해시값을 갖게 되면 길이 n의 linked list가 생성되게 됩니다. 이 때, 특정 key를 찾기 위해서는 길이 n의 linked list를 검색하는 $O(n)$의 시간복잡도와 동일하게 됩니다.
Q. 이중해싱(double hashing)이 무엇인지 설명해 주세요.
**[핵심 답변]**
이중 해싱은 open addressing 방식을 통해 collision을 해결할 때, probing하는 방식중에 하나입니다. linear probing이나 quadratic probing을 통해 탐사할 때는 탐사이동폭이 같기 때문에 클러스터링 문제가 발생할 수 있습니다. 클러스터링 문제가 발생하지 않도록 2개의 해시함수를 사용하는 방식을 이중 해싱이라고 합니다. 하나는 최초의 해시값을 얻을 때 사용하고 또 다른 하나는 해시 충돌이 발생할 때 탐사 이동폭을 얻기 위해 사용합니다.
2. 운영체제 (OS)
Process & Thread
Q. process를 간단히 설명해 주세요.
[핵심 답변]
실행파일(program)이 memory에 적재되어 CPU를 할당받아 실행되는 것을 process라고 합니다.
[면접
💡 운영체제를 관통하는 핵심적인 단어 하나를 뽑는다면 그건 바로 process에요. 운영체제가 작동하는 다양한 원리들이 바로 process를 위해 존재하는 것입니다. 따라서 process의 정의를 잘 이해한다면 앞으로 나올 내용들도 자연스럽게 이해가 가실 거에요!
process를 memory와 CPU관점으로 면접관에게 설명을 하시면 됩니다.
Process
프로세스(process)란 실행중인 프로그램(program in execution)을 뜻합니다. 즉, 실행파일 형태로 존재하던 program이 memory에 적재되어 CPU에 의해 실행(연산)되는 것을 process라고 합니다.
(+ program은 단순히 명령어 리스트를 포함하는 파일입니다.)

Memory에 적재
memory는 CPU가 직접 접근할 수 있는 컴퓨터 내부의 기억장치 입니다. program이 CPU에서 실행되려면 해당 내용이 memory에 적재된 상태여야만 합니다.
프로세스에 할당되는 memory 공간은 Code, Data, Stack, Heap 4개의 영역으로 이루어져 있으며, 각 process마다 독립적으로 할당을 받습니다.

| Code 영역 | 실행한 프로그램의 코드가 저장되는 메모리 영역 |
|---|---|
| Data 영역 | 프로그램의 전역 변수와 static 변수가 저장되는 메모리 영역 |
| Heap 영역 | 프로그래머가 직접 공간을 할당(malloc)/해제(free) 하는 메모리 영역 |
| Stack 영역 | 함수 호출 시 생성되는 지역 변수와 매개 변수가 저장되는 임시 메모리 영역 |
CPU의 연산과 PC register
프로그램의 코드를 토대로 CPU가 실제로 연산을 해야만 프로그램이 실행된다고 볼 수 있습니다. 그럼 어떤 코드를 읽어야 하는가를 정하는 것은 CPU 내부에 있는 PC(Program counter) register에 저장되어 있습니다. PC register에는 다음에 실행될 코드(명령어, instruction)의 주소값이 저장되어 있습니다. 즉, memory에 적재되어있는 process code영역의 명령어중 다음번 연산에서 읽어야할 명령어의 주소값을 PC register가 순차적으로 가리키게 되고, 해당 명령어를 읽어와서 CPU가 연산을 하게 되면 process가 실행이 되는 것입니다.
[꼬꼬무 문답]
Q. process의 memory영역(code, data, stack, heap)에 대해서 설명해 주세요.
**[핵심 답변]**
프로세스가 운영체제에서 할당받는 메모리 공간은 code, data, stack, heap 영역으로 구분됩니다.
- code 영역은 실행한 프로그램의 코드가 저장되는 메모리 영역입니다.
- data 영역은 프로그램의 전역 변수와 static 변수가 저장되는 메모리 영역입니다.
- heap 영역은 프로그래머가 직접 공간을 할당(malloc)/해제(free) 하는 메모리 영역입니다.
- stack 영역은 함수 호출 시 생성되는 지역 변수와 매개 변수가 저장되는 임시 메모리 영역입니다.
Q. ⭐⭐⭐⭐ Multi process에 대해서 설명해 주세요.
[핵심 답변]
Multi process란 2개 이상의 process가 동시에 실행되는 것을 말합니다. 동시에라는 말은 동시성(concurrency)과 병렬성(parallelism) 두 가지를 의미합니다.
동시성은 CPU core가 1개일 때, 여러 process를 짧은 시간동안 번갈아 가면서 연산을 하게 되는 시분할 시스템(time sharing system)으로 실행되는 것입니다.
병렬성은 CPU core가 여러개일 때, 각각의 core가 각각의 process를 연산함으로써 process가 동시에 실행되는 것입니다.
[면접
💡 요새 우리가 쓰는 노트북은 CPU core가 여러개 있죠. core가 여러개여서 실제로 여러 process가 동시에 처리되는 것을 병렬성 이라고 합니다. 하지만 면접에서는 병렬성에 대한 깊은 질문은 거의 나오지 않아요. 다만 병렬성이 어떤 뜻인지 정도만 이해하고 넘어가시면 됩니다.
면접에서 병렬성보다 훨씬 중요한 것은 동시성이에요. 한 개의 CPU core는 당연히 한번에 하나의 연산밖에 못합니다. 그런데 도대체 어떻게 동시에 여러 process를 처리할까요? 정답은 동시성입니다. 동시성을 통해 multi process가 작동되는 원리를 잘 이해하시면 됩니다.
면접에서는 시분할 시스템을 시작으로 context, PCB, context switcing, process의 memory영역을 설명하시면 완벽한 답변이 될거에요.
동시성(Concurrency) vs 병렬성(Parallelism)
| 동시성 | 병렬성 |
|---|---|
| Single core | Multi core |
| 동시에 실행되는 것 같아 보인다. | 실제로 동시에 여러 작업이 처리 된다. |
앞으로 설명할 모든 내용은 Single core의 동시성에 초점을 맞춰져 있습니다.
Multi process
Multi process란 2개 이상의 process가 동시에 실행되는 것을 말합니다. 이 때 process들은 CPU와 메모리를 공유하게 됩니다.
memory의 경우에는 여러 process들이 각자의 memory영역을 차지하여 동시에 적재됩니다.
반면 하나의 CPU는 매 순간 하나의 process만 연산할 수 있습니다. 하지만 CPU의 처리 속도가 워낙 빨라서 수 ms 이내의 짧은 시간동안 여러 process들이 CPU에서 번갈아 실행되기 때문에 사용자 입장에서는 여러 프로그램이 동시에 실행되는 것처럼 보입니다. 이처럼 CPU의 작업시간을 여러 process들이 조금씩 나누어 쓰는 시스템을 시분할 시스템(time sharing system)이라고 부릅니다.
메모리관리
여러 process가 동시에 memory에 적재된 경우, 서로 다른 process의 영역을 침범하지 않도록 각 process가 자신의 memory영역에만 접근하도록 운영체제가 관리해줍니다.

CPU의 연산과 PC register
CPU는 PC(Program counter) register가 가리키고 있는 명령어를 읽어들여 연산을 진행합니다. PC register에는 다음에 실행될 명령어의 주소값이 저장되어 있습니다. multi process시스템에서는 process1이 진행되고 있을 때는 process1의 code 영역을 PC register가 가리키다가, process2가 진행되면 process2의 code 영역을 가리키게 됩니다. CPU는 PC register가 가리키는 곳에 따라 process를 변경해 가면서 명령어를 읽어들이고 연산을 하게 됩니다.
Context
시분할 시스템에서는 한 process가 매우 짧은 시간동안 CPU를 점유하여 일정부분의 명령을 수행하고, 다른 process에게 넘깁니다. 그 후 차례가 되면 다시 CPU를 점유하여 명령을 수행합니다. 따라서 이전에 어디까지 명령을 수행했고, register에는 어떤 값이 저장되어 있었는지에 대한 정보가 필요하게 됩니다. process가 현재 어떤 상태로 수행되고 있는지에 대한 총체적인 정보가 바로 context입니다. context 정보들은 PCB(Process Control Block)에 저장을 합니다.
PCB(Process Control Block)
PCB는 운영 체제가 프로세스를 표현한 자료구조 입니다. PCB에는 프로세스의 중요한 정보가 포함되어 있기 때문에, 일반 사용자가 접근하지 못하도록 보호된 메모리 영역 안에 저장이 됩니다. 일부 운영 체제에서 PCB는 커널 스택에 위치합니다. 이 메모리 영역은 보호를 받으면서도 비교적 접근하기가 편리하기 때문입니다.
PCB에는 일반적으로 다음과 같은 정보가 포함됩니다.
| PCB | |
|---|---|
| Process State | new, running, waiting, halted 등의 state가 있다. |
| Process Number | 해당 process의 number |
| Program counter(PC) | 해당 process가 다음에 실행할 명령어의 주소를 가리킨다 |
| Registers | 컴퓨터 구조에 따라 다양한 수와 유형을 가진 register 값들 |
| Memory limits | base register, limit register, page table 또는 segment table 등 |
| ... |

Context switch
Context switch란 한 프로세스에서 다른 프로세스로 CPU 제어권을 넘겨주는 것을 말합니다.
이 때 이전의 프로세스의 상태를 PCB에 저장하여 보관하고 새로운 프로세스의 PCB를 읽어서 보관된 상태를 복구하는 작업이 이루어집니다.

[꼬꼬무 문답]
Q. process의 context는 무엇인가요?
**[핵심 답변]**
context란 process가 현재 어떤 상태로 수행되고 있는지에 대한 정보입니다. 해당 정보는 PCB(Process Control Block)에 저장을 합니다.
Q. PCB(Process Control Block)에 저장되는 것들은 무엇이 있나요?
**[핵심 답변]**
PCB는 운영체제가 process에 대해 필요한 정보를 모아놓은 자료구조입니다. PCB에는 일반적으로 다음과 같은 정보가 포함됩니다.
- Process number
- Process state
- Program Counter (PC), 레지스터
- CPU 스케쥴링 정보, 우선순위
- 메모리 정보 (해당 process의 주소 공간 등)
Q. Context switch에 대해서 설명해 주세요.
**[핵심 답변]**
Context switch란 한 프로세스에서 다른 프로세스로 **CPU 제어권을 넘겨**주는 것을 말합니다.
이 때 이전의 프로세스의 상태를 **PCB에 저장하여 보관**하고 새로운 프로세스의 **PCB를 읽어서 보관된 상태를 복구**하는 작업이 이루어집니다.
Q. process의 state에는 어떤 것들이 있나요?
**[핵심 답변]**
프로세스는 **실행**(running), **준비**(ready), **봉쇄**(wait, sleep, blocked) 세 가지 상태로 구분됩니다.
| 실행 | 프로세스가 CPU를 점유하고 명령을 수행중인 상태 |
| -- | -------------------------------------------------- |
| 준비 | CPU만 할당받으면 즉시 명령을 수행할 수 있도록 준비된 상태 |
| 봉쇄 | CPU를 할당받아도 명령을 실행할 수 없는 상태 - ex. I/O 작업을 기다리는 경우 등 |
Q. ⭐⭐ Multi thread에 대해서 설명해 주세요.
[핵심 답변]
thread는 한 process 내에서 실행되는 동작(기능 function)의 단위입니다. 각 thread는 속해있는 process의 Stack 메모리를 제외한 나머지 memory 영역을 공유할 수 있습니다.
Multi thread란 하나의 process가 동시에 여러개의 일을 수행할수 있도록 해주는 것입니다. 즉, 하나의 process에서(실행이 된 하나의 program에서) 여러 작업을 병렬로 처리하기 위해 multi thread를 사용합니다. multi thread에서는 한 process 내에 여러 개의 thread가 있고, 각 thread들은 Stack 메모리를 제외한 나머지 영역(Code, Data, Heap) 영역을 공유하게 됩니다.
[면접
💡 thread는 process내에서 독립적인 기능을 수행합니다. 즉, 독립적으로 함수를 호출함을 의미하고 이를 위해 stack memory가 각자 필요한 거에요. thread가 무엇인지 이해하고, multi process와 어떤 점이 다른지를 생각해보면서 공부해보시길 바랍니다.
또한, 독립적인 stack memory와 PC Register가 필요하다는 점을 잘 기억해주세요.
Thread와 multi thread
thread는 process 내에서 독립적인 기능을 수행합니다. 각 thread가 독립적인 기능을 수행한다는 것은 독립적으로 함수를 호출함을 의미합니다.
Stack memory & PC register
thread가 함수를 호출하기 위해서는 인자 전달, Return Address 저장, 함수 내 지역변수 저장 등을 위한 독립적인 stack memory 공간을 필요로 합니다. 결과적으로 thread는 process로부터 Stack memory 영역은 독립적으로 할당받고, Code, Data, Heap 영역은 공유하는 형태를 갖게 됩니다.
또한 multi thread에서는 각각의 thread마다 PC register를 가지고 있어야 합니다. 그 이유는 한 process 내에서도 thread끼리 context switch가 일어나게 되는데, PC register에 code address가 저장되어 있어야 이어서 실행을 할 수 있기 때문입니다.

[꼬꼬무 문답]
Q. thread는 왜 독립적인 stack memory영역이 필요한가요?
**[핵심 답변]**
Stack 영역은 함수 호출 시 전달되는 인자, 함수의 Return Address, 함수 내 지역변수 등을 저장하기 위한 memory 영역입니다. thread가 process내에서 "**독립적인 기능을 실행**”한다는 것은 "**독립적으로 함수를 호출**"함을 의미합니다. 따라서 각 thread가 독립적인 동작을 실행하기 위해서는 각 thread의 stack memory영역이 독립적이여야 합니다.
Q. process와 thread를 비교설명 해주세요.
**[핵심 답변]**
process는 운영체제로부터 자원을 할당받는 작업의 단위이고 thread는 process가 할당받은 자원을 이용하는 실행의 단위입니다. 즉, process는 실행파일(program)이 memory**에 적재**되어 **CPU를 할당**받아 **실행**되는 것입니다. thread는 **한** process **내**에서 실행되는 **동작의 단위**입니다.
process는 memory공간에 code, data, heap, stack영역이 있는데, thread는 process내에서 stack영역을 제외한 code, data, heap영역을 공유합니다.
Q. ⭐⭐ multi process와 multi thread를 비교설명해 주세요.
[핵심 답변]
-
multi thread는 multi process보다 적은 메모리 공간을 차지하고
Context Switching이 빠릅니다. -
multi process는 multi thread보다 많은 메모리공간과 CPU 시간을 차지합니다.
-
multi thread는 동기화 문제와 하나의 thread 장애로 전체 thread가 종료될 위험이 있습니다.
-
multi process는 하나의 process가 죽더라도 다른 process에 영향을 주지 않아 안정성이 높습니다.
[면접
💡 두 방법은 동시에 여러 작업을 수행한다는 측면에서 유사한 면이 있습니다. 적용할 시스템에 따라 두 방법의 장단점을 고려하여 적합한 방식을 선택해야 합니다.
메모리 구분이 필 요할 때는 multi process가 유리합니다. 반면에 Context switching이 자주 일어고 데이터 공유가 빈번한 경우, 그리고 자원을 효율적으로 사용해야 되는 경우에는 multi thread를 사용하는 것이 유리합니다.
비교하여 설명하라는 면접 질문이 나오면 위에 적어드린 내용 안에서 설명을 하시면 됩니다.
Multi process & Multi thread
multi process대신 multi thread로 구현할 경우, 메모리 공간과 시스템 자원 소모가 줄어들게 됩니다. 하지만 multi thread를 사용할 때는 thread간 자원을 공유하기 때문에 동기화문제가 발생할 수 있기 때문에 이를 고려한 프로그램 설계가 필요합니다.
또한 process간의 통신(IPC)보다 thread간의 통신 비용이 적기 때문에 통신으로 인한 오버헤드가 적습니다.
| 메모리 사용 / CPU 시간 | Context switching | 안정성 | |
|---|---|---|---|
| multi process | 많은 메모리 공간 / CPU 시간 차지 | 느림 | 높음 |
| multi thread | 적은 메모리 공간 / CPU 시간 차지 | 빠름 | 낮음 |
⁉️ [참고자료] chrome과 firefox의 차이(multi process vs multi thread)
[꼬꼬무 문답]
Q. multi thread가 multi process보다 좋은 점은 무엇인가요?
**[핵심 답변]**
multi process를 이용하던 작업을 multi thread로 구현할 경우, 메모리 공간과 시스템 자원 소모가 줄어들게 됩니다. 또한 process를 생성하고 자원을 할당하는 등의 system call을 생략할 수 있기 때문에 자원을 효율적으로 관리할 수 있습니다. 뿐만 아니라 Context switching 시 캐시 메모리를 초기화할 필요가 없어서 속도가 빠릅니다.
데이터를 주고 받을 때를 비교해보면, process 간의 통신(IPC)보다 multi thread 간의 통신 비용이 적기 때문에 통신으로 인한 오버헤드가 적습니다.
Q. multi thread가 multi process보다 안좋은 점은 무엇인가요?
**[핵심 답변]**
thread 간의 자원 공유 시 동기화문제가 발생할 수 있어서 프로그램 설계 시 주의가 필요하고, 하나의 thread에 문제가 생기면 process내의 다른 thread에도 문제가 생길 수 있습니다.
Q. ⭐⭐ multi process환경에서 process간에 데이터를 어떻게 주고 받을까요?
[핵심 답변]
원칙적으로 process는 독립적인 주소 공간을 갖기 때문에, 다른 process의 주소 공간을 참조할 수 없습니다. 하지만 경우에 따라 운영체제는 process 간의 자원 접근을 위한 매커니즘인 프로세스 간 통신(IPC, Inter Process Communication)를 제공합니다.
프로세스 간 통신(IPC) 방법으로는 파이프, 파일, 소켓, 공유메모리 등을 이용한 방법이 있습니다.
[면접
💡 IPC는 면접에서도 굉장히 자주 나오는 질문 입니다. multi thread와 다르게 process끼리는 데이터 공유를 하고 있지 않습니다. 따라서 데이터를 주고 받기 위해서 IPC기법을 사용합니다. IPC는 크게 공유메모리 방식과 메시지 전달방식으로 나뉘는데 이 둘의 장단점과 차이점을 중심으로 공부해가시길 바랍니다.
IPC (Inter-Process Communication)
process는 각자 자신만의 독립적인 주소공간을 가지는데, 다른 process가 이 주소공간을 참조하는 것은 허용하지 않습니다. 그렇기 때문에 다른 process와 데이터를 주고받을 수 없습니다. 이를 해결하고자 운영체제는 IPC기법을 통해 process들 간에 통신을 가능하게 해줍니다.
process간 통신(IPC)에는 기본적으로 공유메모리(shared memory)와 메시지 전달(message passing)의 두 가지 모델이 있습니다.
공유메모리(shared memory)
공유 메모리 방식에서는 process들이 주소 공간의 일부를 공유합니다. 공유한 메모리 영역에 읽기/쓰기를 통해서 통신을 수행합니다. process가 공유 메모리 할당을 kernel에 요청하면 kernel은 해당 process에 메모리 공간을 할당해줍니다. 공유 메모리 영역이 구축된 이후에는 모든 접근이 일반적인 메모리 접근으로 취급되기 때문에 더이상 kernel의 도움없이도 각 process들이 해당 메모리 영역에 접근할 수 있습니다. 따라서 커널의 관여 없이 데이터를 통신할 수 있기 때문에 IPC속도가 빠르다는 장점이 있습니다.
공유 메모리 방식은 process간의 통신을 수월하게 만들지만 동시에 같은 메모리 위치에 접근하게 되면 일관성 문제가 발생할 수 있습니다. 이에 대해서는 커널이 관여하지 않기 때문에 process들 끼리 직접 공유 메모리 접근에 대한 동기화 문제를 책임져야 합니다.

메시지 전달(message passing)
메시지 전달 방법은 통상 system call을 사용하여 구현됩니다. kernel을 통해 send(message)와 receive(message)라는 두 가지 연산을 제공받습니다. 예를 들면, process1이 kernel로 message를 보내면 kernel이 process2에게 message를 보내주는 방식으로 동작합니다.
메모리 공유보다는 속도가 느리지만, 충돌을 회피할 필요가 없기 때문에 적은양의 데이터를 교환하는 데 유용합니다. 또, 구현하기가 쉽다는 장점이 있습니다.
대표적인 예시로는 pipe, socket, message queue등이 있습니다.

[꼬꼬무 문답]
Q. IPC의 예시를 들어주실 수 있나요?
**[핵심 답변]**
IPC는 크게 공유 메모리 모델과 메시지 전달 모델로 나눌 수 있습니다. 공유 메모리 모델은 주소 공간의 일부를 공유하며 공유한 메모리 영역에 read/write를 통해 통신하게 되는데, 예시로는 공유메모리와 POSIX가 있습니다. 메시지 전송 모델의 경우에는 kernel을 통해 send/receive 연산을 통해 데이터를 전송합니다. 예시로는 Pipe, socket, message queue 등이 있습니다.
Q. 공유메모리와 메시지 전달 모델의 장단점을 설명해 주세요.
**[핵심 답변]**
공유 메모리 모델은 초기에 공유 메모리 할당을 제외하면 kernel의 관여 없이 통신할 수 있기 때문에 속도가 빠른 장점있습니다. 하지만 여러 process가 동시에 메모리에 접근하는 문제가 발생할 수 있어서 별도의 동기화 과정이 필요하다는 단점이 있습니다.
메세지 전달 모델은 kernel을 통해서 데이터를 주고받기 때문에 통신 속도가 느리다는 단점이 있습니다. kernel에서 제어를 해주기 때문에 안전하며 kernel이 동기화를 제공해준다는 장점이 있습니다.
Q. ⭐ Multi process/thread 환경에서 동기화 문제를 어떻게 해결하나요?
[핵심 답변]
동기화문제를 해결하기 위해 mutex, semaphore 기법 등을 사용할 수 있습니다.
Mutex란 1개의 스레드만이 공유 자원에 접근할 수 있도록 하여, 경쟁 상황(race condition)를 방지하는 기법입니다. 공유 자원을 점유하는 thread가 lock을 걸면, 다른 thread는 unlock 상태가 될 때까지 해당 자원에 접근할 수 없습니다.
Semaphore란 S개의 thread만이 공유 자원에 접근할 수 있도록 제어하는 동기화 기법입니다. Semaphore 기법에서는 정수형 변수 S(세마포) 값을 가용한 자원의 수로 초기화하고, 자원에 접근할 때는 S-- 연산을 수행하여 세마포 값을 감소시키고 자원을 방출할 때는 S++ 연산을 수행하여 세마포 값을 증가시킵니다. 이 때 세마포 값이 0이 되면 모든 자원이 사용 중임을 의미하고, 이후 자원을 사용하려는 프로세스는 세마포 값이 0보다 커질 때까지 block 됩니다.
[면접
💡 mutex와 semaphore는 면접 질문에서 자주 나오는 용어입니다. 이를 설명하기 위해서는 동기화 문제가 무엇이고 왜 발생하는지에 대해서 설명을 할줄 알아야 합니다. multi process/thread 환경에서는 서로 다른 thread가 메모리 영역을 공유하기 때문에 여러 thread가 동일한 자원에 동시에 접근하여 엉뚱한 값을 읽거나 수정하게 되는 동기화 문제가 발생할 수 있습니다. 더 잘 이해하기 위해 atomic operation과 경쟁상황을 살펴보시기 바랍니다.
동기화 문제를 해결하기 위해 임계영역을 설정하고, mutex와 semaphore 기법을 사용합니다. 각 기법의 특징을 중심으로 답변을 하시면 됩니다.
동기화 문제
동기화 문제란 서로 다른 thread가 메모리 영역을 공유하기 때문에 여러 thread가 동일한 자원에 동시에 접근하여 엉뚱한 값을 읽거나 수정하는 문제입니다.
예시를 통해 알아보겠습니다.
count++를 CPU 입장에서 분해해보면 3개의 atomic operations으로 나뉩니다.
count변수의 값을 가져온다.count변수의 값을 1 증가시킨다.- 변경된
count값을 저장한다.
CPU는 atomic operation을 연산하게 됩니다. 따라서 count++을 하기 위해 3번의 연산을 하게 됩니다.
시분할 시스템으로 작동하는 multi process/multi thread 시스템에서, 두 개의 thread가 동일한 데이터인 count에 동시에 접근을 하여 조작을 하는 상황을 가정해보겠습니다. thread1에서도 count++를 하고, thread2에서도 count++를 한다면 그 실행 결과가 접근이 발생한 순서에 따라 달라질 수 있습니다. 이를 경쟁상황(race condition)이라고 합니다.
즉, 둘 이상의 thread가 동일한 자원에 접근하여 조작하고, 그 실행 결과가 접근이 발생한 순서에 따라 달라지는 경쟁상황에 의해서 동기화 문제가 발생할 수 있습니다. 경쟁 상황으로부터 보호하기 위해, 우리는 한 순간에 하나의 process/thread만 해당 자원에 접근하고 조작할 수 있도록 보장해야 합니다. 다시 말해서 process/thread들이 동기화되도록 할 필요가 있습니다.

임계영역(critical section)
둘 이상의 process/thread가 동시에 동일한 자원에 접근하도록 하는 프로그램 코드 부분을 의미합니다. 중요한 특징중 하나는, 한 process/thread가 자신의 임계구역에서 수행하는 동안에는 다른 process/thread들은 그들의 임계구역에 들어갈 수 없어야 한다는 사실 입니다. 즉, 임계영역 내의 코드는 원자적으로(atomically) 실행이 되어야 합니다.
원자적으로 실행 되기 위해서 각각의 process/thread는 자신의 임계구역으로 진입하려면 진입 허가를 요청해야합니다. 이 부분을 entry section이라고 하고, 진입이 허가되면 임계영역을 실행할 수 있습니다. 임계영역이 끝나고 나면 exit section으로 퇴출을 하게 됩니다. 임계영역의 원자성을 보장하여 process/thread들이 동기화되도록 할 수 있습니다.
동기화 방법은 대표적으로 Mutex와 Semaphore가 있습니다.

Mutex
동기화 방법중 하나로 mutual exclusion의 축약어 입니다. 공유자원에 접근할 수 있는 process/thread의 수를 1개로 제한합니다. 임계영역을 보호하고, 경쟁상황을 방지하기 위해 mutex lock을 사용합니다. 즉 process/thread는 임계영역에 들어가기 전에 반드시 lock을 획득해야 하고, 임계구역을 빠져나올 때 lock을 반환해야 합니다.
acquire()함수가 lock을 획득하고 release()함수가 lock을 반환합니다.
acquire() // entry section
// critical section
release() // exit section
busy waiting은 다른 process/thread가 생상적으로 사용할 수 있는 CPU를 낭비한다는 단점이 있습니다.

Semaphore
동기화 방법중 하나로, mutex와 가장 큰 차이점은 공유 자원에 접근할 수 있는 process/thread의 개수가 2개 이상이 될 수 있다는 것입니다.
semaphore 변수 S(세마포)에 동시에 접근 가능한 process/thread의 갯수를 저장합니다. S가 0보다 크면 임계영역으로 들어갈 수 있고, 임계영역에 들어가면 S값을 1 감소시킵니다. S값이 0이 되면 다른 process/thread는 임계영역으로 접근할 수 없습니다. 임계영역에서의 작업이 끝나고 임계영역에서 exit하면서 S값을 1 증가시킵니다.
wait(S) // entry section
// critical section
signal(S) // exit section
semaphore값이 0,1만 가질 수 있는 경우 binary semaphore라고 하는데, 이는 mutex랑 거의 유사하게 작동합니다.

[꼬꼬무 문답]
Q. mutex와 semaphore 기법을 비교 설명해 주세요.
**[핵심 답변]**
mutex는 오직 1개의 process/thread만이 공유 자원에 접근할 수 있고, semaphore는 세마포 변수의 값만큼의 process/thread들이 동시에 자원에 접근할 수 있습니다. mutex는 binary semaphore라고 할 수 있습니다.
Q. 교착상태(Deadlock)에 대해서 간단히 설명해 주세요.
[핵심 답변]
둘 이상의 thread가 각기 다른 thread가 점유하고 있는 자원을 서로 기다릴 때, 무한 대기에 빠지는 상황을 말합니다.
deadlock이 발생하는 조건은 상호 배제(mutual exclusion), 점유 대기(hold-and-wait), 비선점(no preemption), 순환 대기(circular wait)입니다. 이 4가지 조건이 동시에 성립할 때 발생할 수 있습니다.
deadlock 문제를 해결하는 방법에는 무시, 예방, 회피, 탐지-회복의 4가지 방법이 있습니다
[면접
💡 면접에서 deadlock 질문이 나온다면, deadlock이 발생하기 위한 조건과 해결방법을 묻는 것입니다.
deadlock이 발생하는 조건은 상호배제, 점유대기, 비선점, 순환대기 4가지 이고, 이를 해결하는 방법은 무시, 예방, 회피, 탐지-회복 4가지 입니다.
Deadlock 예시

Deadlock 발생 조건
deadlock은 다음 4가지 조건이 동시에 성립할 때 발생할 수 있습니다.
- 상호 배제(mutual exclusion)
- 동시에 한 thread만 자원을 점유할 수 있는 상황입니다.
- 다른 thread가 자원을 사용하려면 자원이 방출될 때까지 기다려야 합니다.
- 점유 대기(hold-and-wait)
- thread가 자원을 보유한 상태에서 다른 thread가 보유한 자원을 추가로 기다리는 상황입니다.
- 비선점(no preemption)
- 다른 thread가 사용 중인 자원을 강제로 선점할 수 없는 상황입니다.
- 자원을 점유하고 있는 thread에 의해서만 자원이 방출됩니다.
- 순환 대기(circular wait)
- 대기 중인 thread들이 순환 형태로 자원을 대기하고 있는 상황입니다.
Deadlock 해결 방법
deadlock 문제를 해결하는 방법에는 (1) 무시, (2) 예방, (3) 회피, (4) 탐지-회복의 4가지 방법이 있습니다.
| 기법 | 설명 | 비고 |
|---|---|---|
| 무시 | deadlock 발생 확률이 낮은 시스템에서 아무런 조치도 취하지 않고 deadlock을 무시하는 방법 | - 무시 기법은 시스템 성능 저하가 없다는 큰 장점이 있습니다. |
-
현대 시스템에서는 deadlock이 잘 발생하지 않고, 해결 비용이 크기 때문에 무시 방법이 많이 사용됩니다. | | 예방 | 교착 상태의 4가지 발생 조건중 하나가 성립하지 않게 하는 방법 | - 순환 대기 조건이 성립하지 않도록 하는 것이 현실적으로 가능한 예방 기법입니다.
-
자원 사용의 효율성이 떨어지고 비용이 큽니다. | | 회피 | thread가 앞으로 자원을 어떻게 요청할지에 대한 정보를 통해 순환 대기 상태가 발생하지 않도록 자원을 할당하는 방법 | - 자원 할당 그래프 알고리즘, 은행원 알고리즘 등을 사용하여 자원을 할당하여 deadlock을 회피합니다. | | 탐지-회복 | 시스템 검사를 통해 deadlock 발생을 탐지하고, 이를 회복시키는 방법 | - 자원 사용의 효율성이 떨어지고 비용이 큽니다. |
[꼬꼬무 문답]
Q. deadlock은 언제 발생하게 되나요?
**[핵심 답변]**
deadlock은 상호 배제(mutual exclusion), 점유 대기(hold-and-wait), 비선점(no preemption), 순환 대기(circular wait)의 4가지 조건이 **동시에 성립**할 때 발생할 수 있습니다.
상호 배제는 동시에 한 thread만 자원을 점유할 수 있는 상황이고, 점유 대기는 thread가 자원을 보유한 상태에서 다른 thread가 보유한 자원을 추가적으로 기다리는 상황입니다. 또 비선점은 다른 thread가 사용 중인 자원을 강제로 선점할 수 없는 상황을 뜻하고, 순환 대기는 대기 중인 thread들이 순환 형태로 자원을 대기하는 상황을 말합니다.
Memory
Q. paging이란 뭔가요?
[핵심 답변]
paging이란 process가 할당받은 메모리 공간을 일정한 page 단위로 나누어, 물리 메모리에서 연속되지 않는 서로 다른 위치에 저장하는 메모리 관리 기법입니다.
[면접
💡 면접에서 자주나오진 않지만, 중요한 내용들이 많이 있어서 알아두면 깊이있는 질문이 나올 때 잘 답변을 하실 수 있습니다.
특히 논리적주소와 물리적주소의 차이를 이해해야하고, 물리 메모리의 연속되지 않는 서로 다른 위치에 page단위만큼 저장한다는 점을 설명할 수 있어야 합니다.
[용어정리] - 논리적 주소(logical address)란?
process가 memory에 적재되기 위한 독자적인 주소 공간인 논리적 주소(logical address)가 생성됩니다. 논리적 주소는 각 process마다 독립적으로 할당되며, 0번지부터 시작됩니다.
[용어정리] - 물리적 주소(physical address)란?
물리적 주소(physical address)는 process가 실제로 메모리에 적재되는 위치를 말합니다.
[용어정리] - 주소 바인딩(address binding)이란?
CPU가 기계어 명령을 수행하기 위해 process**의 논리적 주소가 실제 물리적 메모리의 어느 위치에 매핑되는지 확인하는 과정**을 주소 바인딩(address binding)이라고 합니다.
Paging
paging 기법은 process의 메모리 공간을 동일한 크기의 page 단위로 나누어 물리적 메모리의 서로 다른 위치에 page들을 저장하는 메모리 관리 기법입니다. paging 기법에서는 물리적 메모리를 page와 같은 크기의 frame으로 미리 나누어둡니다.
paging 기법에서는 주소 바인딩(address binding)을 위해 모든 프로세스가 각각의 주소 변환을 위한 page table을 갖습니다.


[꼬꼬무 문답]
Q. paging 기법 사용시 발생할 수 있는 메모리 단편화(Memory fragmentation) 문제에 대해 설명하시오
**[핵심 답변]**
물리적 메모리 공간이 작은 조각으로 나눠져서 메모리가 충분히 존재함에도 할당이 불가능한 상태를 보고 메모리 단편화가 발생했다고 말합니다.
paging 기법에서는 process의 논리적 주소 공간과 물리적 메모리가 같은 크기의 page 단위로 나누어지기 때문에 외부 단편화 문제가 발생하지 않습니다. 하지만 process 주소 공간의 크기가 page 크기의 배수라는 보장이 없기 때문에, 프로세스의 주소 공간 중 가장 마지막에 위치한 page에서는 내부 단편화 문제가 발생할 가능성이 있습니다.
Q. segmentation에 대해서 설명해 주세요.
[핵심 답변]
segmentation이란 process가 할당받은 메모리 공간을 논리적 의미 단위(segment)로 나누어, 연속되지 않는 물리 메모리 공간에 할당될 수 있도록 하는 메모리 관리 기법입니다.
[면접
💡 page와 같이 면접에 자주나오진 않지만, 메모리에 대해서 이해하는데 중요한 내용이 많이 담겨져 있기 때문에 알아두시면 좋습니다.
일정한 크기의 단위로 나누어 할당을 했던 page와 다르게, segmentation은 의미 단위로 물리 메모리에 할당을 하는 기법임을 설명할 수 있어야 합니다. 특히 code, data, heap, stack등의 기능(의미)단위로 나눈다는 점을 기억하시길 바랍니다.
Segmentation
segmentation 기법은 process가 할당받은 메모리 공간을 **논리적 의미 단위(segment)**로 나누어, 연속되지 않는 물리 메모리 공간에 할당될 수 있도록 하는 메모리 관리 기법입니다.
일반적으로 process의 메모리 영역 중 Code, Data, Heap, Stack 등의 기능 단위로 segment를 정의하는 경우가 많습니다.
segmentation 기법에서는 주소 바인딩(address binding)을 위해 모든 프로세스가 각각의 주소 변환을 위한 segment table을 갖습니다.

[꼬꼬무 문답]
Q. segmentation의 메모리 단편화(Memory fragmentation) 문제에 대해 설명해 주세요.
**[핵심 답변]**
segmentation 기법에서 segment의 크기만큼 메모리를 할당하므로 내부 단편화 문제가 발생하지 않습니다. 하지만 서로 다른 크기의 segment들이 메모리에 적재되고 제거되는 일이 반복되면, 외부 단편화 문제가 발생할 가능성이 있습니다.
Q. paging과 segmentation의 차이는 뭔가요?
paging은 일정한 크기의 단위로 나누어 할당을 하는데, 이에 반해 segmentation은 code, data, heap, stack등의 기능(의미)단위로 물리 메모리에 할당을 하는 기법입니다.
paging의 경우 내단편화의 문제가 발생할 수 있는데, 이에 반해 segmentation은 외단편화의 문제가 발생할 수 있습니다.
Q. paged segmentation 기법에 대해 설명하시오
**[핵심 답변]**
paged segmentation이란 segmentation을 기본으로 하되 이를 다시 동일 크기의 page로 나누어 물리 메모리에 할당하는 메모리 관리 기법입니다. 즉, 프로그램을 **의미 단위의 segment**로 나누고 개별 **segment의 크기를 page의 배수**가 되도록 하는 방법입니다.
이를 통해 segmentation 기법에서 발생하는 **외부 단편화 문제를 해결**하고, 동시에 segment 단위로 process 간의 공유나 process 내의 접근 권한 보호가 이루어지도록 해서 paging 기법의 단점을 해결합니다.
Q. ⭐ 가상 메모리에 대해서 설명해 주세요.
[핵심 답변]
가상 메모리(virtual memory)란 process 전체가 메모리에 올라오지 않더라도 실행이 가능하도록 하는 기법입니다. 가상 메모리 기법을 통해 사용자 프로그램이 물리적 메모리보다 커져도 실행이 가능하다는 장점이 있습니다.
[면접
💡 운영체제에서 메모리 관련된 면접문제는 이 안에서 다 나온다고 생각하시면 됩니다. 실제 우리가 사용하고 있는 운영체제에서는 가상메모리를 사용하고 있기 때문에 가상메모리를 이해하는 것은 개발자에게 중요합니다. 운영체제에 의해서 메모리 관리가 어떻게 이뤄지고 있는지, 가상메모리가 무엇인지, page fault는 무엇이고 page 교체 알고리즘에는 어떤 것들이 있는지 잘 이해하시기 바랍니다.
가상메모리(virtual memory)
가상메모리는 실제의 물리 메모리 개념과 개발자 입장의 논리 메모리 개념을 분리한 것입니다. 이렇게 함으로써 개발자가 메모리 크기에 관련한 문제를 염려할 필요 없이 쉽게 프로그램을 작성할 수 있게 해줍니다.
운영체제는 가상 메모리 기법을 통해 프로그램의 논리적주소 영역에서 필요한 부분만 물리적 메모리에 적재하고, 직접적으로 필요하지 않은 메모리 공간은 디스크(Swap 영역)에 저장하게 됩니다.

요구 페이징(demand paging)
당장 사용될 주소 공간을 page 단위로 메모리에 적재하는 방법을 **요구 페이징(demand paging)**이라고 합니다. 요구 페이징 기법에서는 특정 page에 대해 cpu의 요청이 들어온 후에 해당 page를 메모리에 적재합니다. 당장 실행에 필요한 page만을 메모리에 적재하기 때문에 메모리 사용량이 감소하고, 프로세스 전체를 메모리에 적재하는 입출력 오버헤드도 감소하는 장점이 있습니다.
요구 페이징 기법에서는 **유효/무효 비트(valid/invalid bit)**를 두어 각 page가 메모리에 존재하는지 표시하게 됩니다.
Page fault
CPU가 무효 비트(invalid bit)로 표시된 page에 엑세스하는 상황을 page fault라고 합니다.
CPU가 무효 page에 접근하면 주소 변환을 담당하는 하드웨어인 MMU가 page fault trap을 발생시키게 되고, 다음과 같은 순서로 page fault를 처리하게 됩니다.
- CPU가 페이지 N을 참조합니다.
- Page table에서 페이지 N이 무효 상태임을 확인합니다.
- MMU에서 Page fault trap이 발생시킵니다.
- 디스크에서 페이지 N을 빈 프레임에 적재하고 page table을 업데이트합니다.(invalid→ valid)

page 교체 알고리즘(replacement algorithm)
page fault가 발생하면, 요청된 page를 디스크에서 메모리로 가져옵니다. 이 때, 물리적 메모리에 공간이 부족할 수 있습니다. 그럴 경우에는 메모리에 올라와 있는 page를 디스크로 옮겨서 메모리 공간을 확보해야 합니다. 이것을 페이지 교체(page replacement)라고 하고, 어떤 page를 교체할 것이냐를 결정하는 알고리즘이 page교체 알고리즘(replacement algorithm)입니다.
교체 알고리즘은 최대한 page fault가 적게 일어나도록 도와줘야 합니다. 따라서 앞으로 참조될 가능성이 적은 page를 선택해서 교체하는 것이 성능을 향상시키는 방법입니다.
| 알고리즘 | 설명 |
|---|---|
| FIFO(First In First Out) | 메모리에 올라온지 가장 오래된 page를 교체한다. |
| 최적 페이지 교체 | 앞으로 가장 오랫동안 사용되지 않을 page를 찾아 교체한다. 실제구현은 어렵다 |
| LRU(Least Recently Used) | 가장 오랫동안 사용되지 않은 page를 교체한다. |
| LFU(Least Frequently Used) | 참조 횟수가 가장 적은 page를 교체한다. 비용대비 성능이 좋지 않아 잘 쓰이진 않는다. |
[꼬꼬무 문답]
Q. 요구페이징(demand paging)이란 무엇인가요?
**[핵심 답변]**
요구 페이징 기법은 특정 page에 대해 cpu의 요청이 들어 왔을 때 해당 page를 메모리에 적재합니다. 당장 실행에 필요한 page만을 메모리에 적재하기 때문에 메모리 사용량이 감소하고, 프로세스 전체를 메모리에 적재하는 입출력 오버헤드도 감소하는 장점이 있습니다
Q. 페이지 교체 알고리즘(replacement algorithm)을 아는대로 말씀해주세요.
**[핵심 답변]**
FIFO, 최적 페이지 교체, LRU, LFU 등이 있습니다.
Q. LRU알고리즘과 LFU 알고리즘을 비교 설명해 주세요.
**[핵심 답변]**
LRU는 Least Recently Used의 약자로, 가장 오래전에 참조가 이루어진 page를 교체합니다.
LFU는 Least Frequently Used의 약자로, 물리적 메모리 내에 존재하는 page 중에서 지금까지의 참조횟수가 가장 적은 page를 교체합니다.
세마포어의 한계점 s++ s-- 락을 가지고 있으면 하나의 스레드가 기다려야하는데 계속 기다리니까 cpu를 쓰니까 busywaiting을 발생 해결법은 block and wait 방식이 있다. 자원이 없거나 기다리는 경우 sleep 자원을 할당받을 수 있으면 wake up
https://choiblack.tistory.com/23
atomic 싱크로나이즈
3. 데이터베이스
DB 구조 & 설계
Q. Primary key가 무엇인지 설명해 주세요.
[핵심 답변]
candidate key 중 선택한 main key로써, 각 row를 unique하게 구분하는 column(또는 column의 집합)을 말합니다. 그래서 기본키는 Null 값을 가질 수 없고, 중복된 값을 가질 수 없습니다. 기본키는 table당 1개만 지정해야합니다.
[면접
💡 key와 관련된 기본적인 용어를 묻는 면접관들도 꽤 있습니다. 데이터베이스에서 가장 기초적인 용어들이기 때문에 대답을 하지 못하면 말이 안되겠죠! 확실하게 이해하고 넘어가면 틀릴 일이 없으므로 이번 시간에 확실히 짚고 넘어 가보겠습니다.
특히 꼬꼬무에서 처럼 후보키는 뭔지, 대체키는 뭔지, 복합키는 뭔지 묻는 경우도 많으므로 간략히 한 줄로 설명하실 수 있으면 됩니다.
Relation
table 중 데이터베이스에서 사용되기 위한 조건을 갖춘 것이 relation입니다.
Relation의 제약 조건 중 가장 자주 등장하는 조건은 다음과 같습니다.
- table의 cell은 단일 값을 갖는다.
- 어떤 두 개의 row도 동일하지 않다.
하지만 통상적으로 relation과 table이란 용어를 구분하지 않고 사용하기도 합니다.

Primary key
**Super Key(슈퍼키)**는 각 row를 유일하게 식별할 수 있는 하나 또는 그 이상의 속성들의 집합입니다. 슈퍼키는 유일성만 만족하면 슈퍼키가 될 수 있습니다.
- 유일성 : 하나의 key 값으로 특정 row만을 유일하게 찾아낼 수 있어야 합니다.
- 예시
- (학번)
- (학번,이름)
- (학번, 이름, 학과)
- (주민등록번호)
- (주민등록번호, 학과, 성별)
- 등등
**Candidate key(후보키)**는 Super key 중에서 더이상 쪼개질 수 없는 Superkey를 Candidate Key라고 합니다. 즉 각 row를 유일하게 식별할 수 있는 최소한의 속성들의 집합입니다.
- 최소성 : 모든 row를 유일하게 식별하는데 꼭 필요한 속성만으로 구성되어야 합니다.
- 예시
- (학번)
- (주민등록번호)
**Primary key(기본키)**는 candidate key 중 선택한 main key로써, 각 row를 구분하는 유일한 열을 말합니다. 그래서 기본키는 Null 값을 가질 수 없고, 중복된 값을 가질 수 없습니다. 기본키는 table당 1개만 지정해야합니다.
Alternative key(대체키) 는 후보키가 두 개 이상일 경우, 기본키로 지정이 되지 못하고 남은 후보키들을 말합니다.

[꼬꼬무 문답]
Q. Primary Key와 Foreign Key에 대해 설명해 주세요.
**[핵심 답변]**
Primary key는 **candidate key 중 선택한 main key**로써, Null 값을 가질 수 없고, 중복된 값을 가질 수 없습니다. Candidate key 중 선택했으므로 **유일성**과 **최소성**을 만족합니다.
Foreign key는 다른 table의 Primary key column과 연결되는(참조되는) table의 column을 의미합니다
Q. Candidate key에 대해 설명하시오
**[핵심 답변]**
Candidate key는 table을 구성하는 column들 중에서 최소성과 유일성을 만족하는 column 또는 column의 집합입니다. 즉 **primary key로 사용할 수 있는 column**들을 말합니다.
Q. alternate key에 대해 설명하시오.
**[핵심 답변]**
primary key를 제외한 **나머지 candidate key**들을 말합니다. 대체키/보조키라고도 부릅니다.
Q. composite key에 대해 설명하시오
**[핵심 답변]**
Composite key란 table에서 각 row를 식별할 수 있는 **두 개 이상의 column으로 구성된 candidate key**를 말합니다.
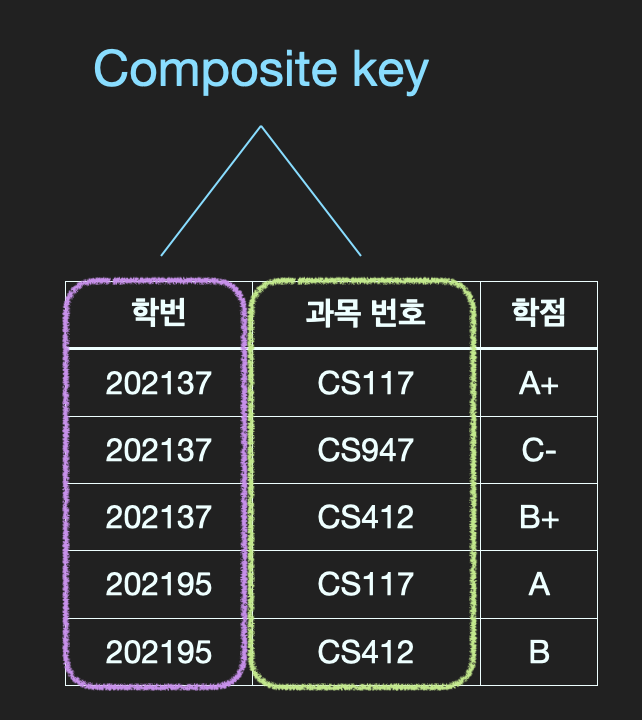
Q. 관계형 데이터베이스의 N:M 관계에 대해서 설명해 주세요.
[핵심 답변]
관계형 데이터베이스에서 양쪽 entity 모두가 서로에게 1:N 관계를 갖는 구조를 말합니다.
[면접
💡 N:M 관계는 실제 프로젝트에서 자주 쓰이면서도 제대로 이해하기 어려울 수 있는 내용입니다. 따라서 실제 프로젝트에서 마주할 수 있는 상황을 예시로 주면서 N:M 관계로 데이터베이스를 설계해 보라는 질문을 종종 받게 됩니다.
따라서 예시를 통해 N:M 설계를 어떻게 할지를 생각하면서 학습하시길 바랍니다.
1:N
관계형 데이터베이스에서 하나의 entity(table)가 관계를 맺은 entity의 여러 객체를 가질 수 있는 구조를 말합니다.
두 table간의 관계를 mapping cardinality로 표현하고, 종류는 크게 다음과 같습니다.
- 1:1
- 1:N
- N:M
실무에서 가장 자주 등장하는 1:N 구조인 고객-주문 관계를 살펴보겠습니다.


1:N 구조에서는 보통 primary key - foreign key를 사용하여 관계를 맺습니다.
**Foreign key(외래키)**는 다른 table의 Primary key column과 연결되는(참조되는) table의 column을 의미합니다. 즉, 두 table을 연결할 때 한 table의 외래키가 다른 하나의 table의 기본키가 됩니다.
그림의 예시와 같은 상황에서 고객의 정보가 변경된다고 해도, 주문내역 table은 수정할 필요가 전혀 없게 되어 효율적인 데이터베이스 운영이 가능해집니다.
N:M
관계형 데이터베이스에서 양쪽 entity 모두가 서로에게 1:N 관계를 갖는 구조를 말합니다.
N:M 구조에서는 보통 새로운 table(Mapping table)을 통해서 관계를 맺습니다. 가장 친숙한 N:M 구조인 학생-수업 관계를 살펴보겠습니다.


[꼬꼬무 문답]
Q. 1:N 관계에 대해서 설명해 주세요.
**[핵심 답변]**
관계형 데이터베이스에서 하나의 entity(table)가 **관계를 맺은 entity의 여러 객체를 가질** 수 있는 구조를 말합니다.
Q. left outer join, inner join 차이를 설명해 주세요
[핵심 답변]
Join이란 두 개 이상의 테이블을 서로 연결하여 하나의 결과를 만들어 보여주는 것을 말합니다.
inner join(또는 join)은 두 테이블에 모두 있는 내용만 join되는 방식입니다.
left outer join(또는 left join)은 왼쪽 table의 모든 행에 대해서 join을 진행합니다.
[면접
💡 Join중에 가장 자주 사용되는 inner join과 left outer join 을 제대로 이해하고, 사용할 수 있는지 묻는 질문입니다. Join은 실무에서도 자주 사용되기 때문에 면접 질문으로도 가끔 나옵니다. 따라서 둘의 차이점을 간결하게 설명하면 됩니다.
Inner Join(내부조인)
두 테이블을 연결할 때 가장 많이 사용되는 것이 inner join입니다. inner join은 줄여서 join으로 부르기도 합니다. 두 테이블을 join하기 위해서는 두 테이블이 1:N 관계로 연결되어야 합니다. 1:N 관계는 주로 primary key와 foreign key 관계로 맺어져 있습니다. (상호조인의 경우에는 PK-FK 관계가 아니여도 됩니다.)

[SQL JOIN 예시]
- vedio table
| id | title | y_id |
|---|---|---|
| 1 | 데이터베이스 완전정복 | 2 |
| 2 | 볼리비아 광산 탐방기 | 4 |
| 3 | 침vs펄 토론 | 3 |
| 4 | 운영체제 완전 정복 | 2 |
| 5 | 충격실화 대한민국이 해냈다 | Null |
- youtuber table
| id | name | 채널 설명 |
|---|---|---|
| 1 | 쯔양 | 먹방 |
| 2 | 개발남노씨 | 개발 |
| 3 | 침착맨 | 예능 |
| 4 | 빠니보틀 | 여행 |
select * from vedio inner join youtuber on vedio.y_id = youtuber.id;
| id | title | y_id | name | 채널 설명 |
|---|---|---|---|---|
| 1 | 데이터베이스 완전정복 | 2 | 개발남노씨 | 개발 |
| 2 | 볼리비아 광산 탐방기 | 4 | 빠니보틀 | 여행 |
| 3 | 침vs펄 토론 | 3 | 침착맨 | 예능 |
| 4 | 운영체제 완전 정복 | 2 | 개발남노씨 | 개발 |
두 table에 공통된 데이터가 존재하는 행에 대해서만 데이터를 검색합니다.
left outer join(외부조인)
select * from vedio left join youtuber on vedio.y_id = youtuber.id;
| id | title | y_id | name | 채널 설명 |
|---|---|---|---|---|
| 1 | 데이터베이스 완전정복 | 2 | 개발남노씨 | 개발 |
| 2 | 볼리비아 광산 탐방기 | 4 | 빠니보틀 | 여행 |
| 3 | 침vs펄 토론 | 3 | 침착맨 | 예능 |
| 4 | 운영체제 완전 정복 | 2 | 개발남노씨 | 개발 |
| 5 | 충격실화 대한민국이 해냈다 | Null | Null | Null |
왼쪽 vedio table의 모든 데이터를 포함한 데이터를 검색합니다.
Q. ⭐ RDB - NoSQL를 비교 설명해 주세요.
[핵심 답변]
**관계형 데이터베이스(RDB)**는 사전에 엄격하게 정의된 DB schema를 요구하는 table 기반 데이터 구조를 갖습니다.
**NoSQL(비관계형 데이터베이스)**은 table 형식이 아닌 비정형 데이터를 저장할 수 있도록 지원합니다.
RDB는 엄격한 schema로 인해 데이터 중복이 없기 때문에 데이터 update가 많을 때 유리합니다.
NoSQL의 경우 데이터 중복으로 인해 데이터 update 시 모든 컬렉션에서 수정이 필요하기 때문에 update가 적고 조회가 많을 때 유리합니다.
[면접
💡 RDB를 아직 많이 쓰고 있지만 점차 NoSQL를 도입하는 영역이 넓어지고 있습니다. 따라서 프로젝트마다 RDB vs NoSQL중에 더 유리한 것을 채택해서 사용해야 하는데, 이를 위해서는 장단점과 어떤 차이가 있는지를 명확히 알아야 합니다.
이 질문은 면접에서 꽤 자주 나오는 질문이기 때문에 면접 보기 전에 꼭 알고 가시기 바랍니다!
Key-value storage system ( NoSQL )
기존의 관계형 database의 경우에는 단일 기업의 데이터를 다루는데 최적화 되어 있습니다. 하지만 최신 데이터들은 꼭 관계형으로 처리될 필요가 없는 경우도 많고, 다뤄야 하는 데이터의 양도 훨씬 커졌습니다. 즉 Big data라고 일컬어 지는 많은 양의 데이터를를 처리하기 위한 방법으로 다양한 해결책이 나왔는데, 그 중 하나의 방법이 Key-value storage system 입니다.
Key-value stores는 NoSQL system이라고도 불립니다. 그 이유는 SQL을 보통 지원하지 않고 transaction을 지원하지 않는 등 SQL을 사용하는 기존의 RDB와의 차이점 때문입니다.
MongoDB
NoSQL의 종류는 Bigtable, DynamoDB, Cassandra, MongoDB등이 있습니다. 그 중 MongoBD의 예시를 보면서 NoSQL이 어떻게 작동하는지 간단하게 살펴보겠습니다.
db.createCollection("student")
db.student.insert({"id": 2022394, "name": "Nossi", "class": ["Math", "Eng"]})
db.student.insert({"id": 2021921, "name": "Bob", "class": ["Eng"]})
db.student.find() // Fetch all students in JSON format
db.student.findOne({"id": 2022394}) // Find one matching student
db.student.remove({"name": "Nossi"}) // Delete matching students
db.student.drop() // Drops the entire collection
RDB vs NoSQL
| RDB (SQL) | NoSQL | |
|---|---|---|
| 데이터 저장 모델 | table | json document / key-value / 그래프 등 |
| 개발 목적 | 데이터 중복 감소 | 애자일 / 확장가능성 / 유연성 |
| 예시 | Oracle, MySQL, PostgreSQL 등 | MongoDB, DynamoDB 등 |
| Schema | 엄격한 데이터 구조 | 유연한 데이터 구조 |
| ⭐장점⭐ | - 명확한 데이터구조 보장 |
- 데이터 중복 없이 한 번만 저장 (무결성)
- 데이터 중복이 없어서 데이터 update 용이 | - 유연하고 자유로운 데이터 구조
- 새로운 필드 추가 자유로움
- 수평적 확장(scale out) 용이 | | ⭐단점⭐ | - 시스템이 커지면 Join문이 많은 복잡한 query가 필요
- 수평적 확장이 까다로워 비용이 큰 수직적 확장(Scale up)이 주로 사용됨.
- 데이터 구조가 유연하지 못함 | - 데이터 중복 발생 가능
- 중복 데이터가 많기 때문에 데이터 변경 시 모든 컬렉션에서 수정이 필요함
- 명확한 데이터구조 보장 X | | ⭐사용⭐ | - 데이터 구조가 변경될 여지가 없이 명확한 경우
- 데이터 update가 잦은 시스템 (중복 데이터가 없으므로 변경에 유리) | - 정확한 데이터 구조가 정해지지 않은 경우
- Update가 자주 이루어지지 않는 경우 (조회가 많은 경우)
- 데이터 양이 매우 많은 경우 (scale out 가능) |
수직적 확장Scale-up vs 수평적 확장 Scale-out
DB와 비교하여 NoSQL의 특징은 ACID, Transaction을 지원하지 않는다는 것입니다. RDB는 ACID와 Transaction을 보장하기 위해 수평적 확장이 쉽지가 않습니다. 또한 RDB 같은 경우에는 multiple server로 수평적 확장을 하게 되면 join을 하기 위해 굉장히 복잡한 과정이 필요합니다.
RDB도 수평적 확장이 가능하지만 NoSQL에 비해 훨씬 복잡합니다. RDB를 수평적 확장하려면 샤딩(sharding)(데이터가 수평적으로 분할되고 기기의 모음 전반에 걸쳐 분산되는 경우)이 필요합니다. ACID 준수를 유지하면서 RDB를 샤딩하는 것은 매우 까다로운 작업입니다.
[꼬꼬무 문답]
Q. Nosql은 언제 사용하면 좋을까요?
[핵심 답변]
NoSQL은 정확한 데이터 구조가 정해지지 않은 경우, 데이터 update가 자주 이루어지지 않고 조회가 많은 경우, 또 scale out이 가능하므로 데이터 양이 매우 많은 경우에 사용하면 좋습니다.
Q. RDB는 언제 사용하면 좋을까요?
[핵심 답변]
RDB는 데이터 구조가 명확하여 변경될 여지가 없는 경우, 또 데이터 중복이 없으므로 데이터 update가 잦은 시스템에서 사용하면 좋습니다.
Transaction
Q. ⭐⭐ Transaction을 간단히 설명해 주세요.
[핵심 답변]
transaction는 데이터베이스 내에서 수행되는 작업의 최소 단위로, 데이터베이스의 무결성을 유지하며 DB의 상태를 변화시키는 기능을 수행합니다. transaction은 하나 이상의 query를 포함해야 하고, ACID라고 칭해지는 원자성, 일관성, 고립성, 지속성의 4가지 규칙을 만족해야합니다.
[면접
💡 데이터베이스 면접질문에서 Index다음으로 가장 자주 나오는 질문이 Transaction과 Deadlock 입니다. 데이터베이스의 transaction이 안전하게 수행된다는 것을 보장하기 위한 성질 4가지 ACID를 종종 물어봅니다. Transaction에 대한 설명과 ACID가 무엇을 뜻하는지를 정확하게 이해하고 가시면 됩니다.
Transaction
은행 시스템에서 A가 100만원을 출금해서 B에게 입금하는 상황을 생각해 보겠습니다. A의 잔고에서 100만원을 출금하였는데, 이 때 전산오류가 생겨서 B의 계좌에는 100만원이 입금 되지 않았습니다. 이런 상황은 전산시스템의 치명적인 오류입니다. 이렇게 예상치 못하게 오류가 발생하여 하여 데이터의 부정합이 발생하는 경우, 다시 원상복귀 해야합니다. 따라서 모든 입출금은 하나의 묶음 형태로 작동해야 합니다. 출금을 했으면 입금을 마치던지 아니면 아예 없던 일이 되어야 합니다. 이런 식으로 두 행위는 분리될 수 없는 하나의 거래로 처리돼야 하는 단일 업무 입니다. 이러한 업무 처리의 최소 단위를 데이터베이스에서는 transaction이라고 합니다.
데이터베이스에서 Transaction이 필요한 이유는 데이터를 다룰 때 장애가 일어나는 경우 transaction은 장애 발생시 데이터를 복구하는 작업의 단위가 되기 때문입니다. 또한 데이터베이스에서 여러 작업이 동시에 같은 데이터를 다룰 때가 있습니다. transaction을 통해 이 작업을 서로 분리하고, 이를 통해 오류가 발생하지 않게 합니다. DBMS는 transaction이 이러한 규칙을 유지하도록 지원합니다.
START TRANSACTION
// (1) A 계좌 잔액 가져옴 A = 1000
// (2) B 계좌 잔액 가져옴 B = 1000
// (3) A 출금 A = A - 100
// (4) B 입금 B = B + 100
UPDATE Customer SET balance = balance - 100 WHERE name='A';
UPDATE Customer SET balance = balance + 100 WHERE name='B';
//COMMIT
// (5) A 계좌 잔액 저장 A = 900
// (6) B 계좌 잔액 저장 B = 1100
COMMIT
ACID
트랜잭션은 데이터베이스의 무결성을 유지하기 위해 원자성, 일관성, 고립성, 지속성의 성질을 갖습니다.
-
Atomicity(원자성) : transaction에 포함된 작업은 전부 수행되거나 아니면 전부 수행되지 말아야 합니다.(all or nothing)
-
Consistency(일관성): transaction이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 유지하는 것을 의미한다. 송금 전후 모두 잔액의 data type은 integer이여야 한다는 것이 일관성의 한 예가 될 수 있습니다.
-
Isolation(고립성): 여러 Transaction은 동시에 수행됩니다. 이때 각 transaction은 다른 transaction의 연산 작업이 끼어들지 못하도록 보장하여 독립적으로 작업을 수행합니다. 따라서 동시에 수행되는 transaction이 동일한 data를 가지고 충돌하지 않도록 제어해줘야 합니다. 이를 동시성제어(concurrency control) 라고합니다.
-
Durability(지속성): 성공적으로 수행된 transaction은 데이터베이스에 영원히 반영되어야 함을 의미합니다. transaction이 완료되어 저장이 된 데이터베이스는 저장 후에 생기는 정전, 장애, 오류 등에 영향을 받지 않아야 합니다.

동시성 제어(concurrency control)
여러 개의 transaction이 한 개의 데이터를 동시에 갱신(update)할 때 어느 한 transaction의 갱신이 무효화 될 수 있는데 이를 갱신손실이라고 합니다. 동시성제어를 통해 갱신손실을 미리 막을 수 있습니다. 즉, transaction이 동시에 수행될 때 일관성을 해치지 않도록 transaction의 데이터 접근을 제어하는 DBMS의 기능을 동시성제어라고 합니다.
갱신손실 문제를 해결하기 위한 방법중에 하나로 데이터를 수정중에 있는 transaction은 해당 데이터를 Lock으로 잠금장치를 하여 다른 Transaction이 접근하지 못하게 하는 방법이 있습니다. Lock이 걸린 데이터는 Unlock이 될 때까지 다른 Transaction들은 접근하지 못하고 기다려야 합니다.


[꼬꼬무 문답]
Q. COMMIT과 ROLLBACK에 대해 설명해보세요.
**[핵심 답변]**
데이터베이스는 COMMIT과 ROLLBACK 명령어를 통해 **데이터 무결성을 보장**합니다. COMMIT이란 transaction 작업을 완료했다고 확정하는 명령어입니다. transaction 작업 내용을 실제 DB에 저장하고, DB가 변경됩니다. ROLLBACK은 작업 중 문제가 발생했을 때, transaction 처리 과정에서 발생한 **변경 사항을 취소**하고, 이전 COMMIT의 상태로 되돌립니다.
Q. 원자성(일관성, 고립성, 지속성)이 뭔가요?
**[핵심 답변]**
transaction에 포함된 작업은 전부 수행되거나 아니면 전부 수행되지 말아야 합니다.*(all or nothing)*
Q. ⭐ DeadLock이란 무엇인지 설명해 주세요.
[핵심 답변]
데이터베이스 deadlock(교착 상태)이란, 여러 transaction들이 각각 자신의 데이터에 대하여 lock을 획득한 상태에서 상대방 데이터에 대하여 접근하고자 대기를 할 때 교차 대기를 하게 되면서 서로 영원히 기다리는 상태를 말합니다.
[면접
💡 면접에서 종종 나오는 질문으로, deadlock은 어떤 상황에 발생하는지 그리고 해결 방법은 어떻게 되는지에 초점을 맞춰서 답변을 준비하시면 됩니다.
Deadlock
두 transaction이 각각 lock을 설정하고, unlock을 하지 않은 상태에서 서로의 lock이 걸린 데이터에 접근하려고 할 때, 서로 대기를 계속하여 영원히 처리되지 않는 상황이 발생합니다.
deadlock을 해결하는 방법은 다음과 같습니다.
- 예방기법: 각 transaction이 실행되기 전에 필요한 데이터를 모두 Locking 해주는 것입니다. 하지만 locking해줘야 하는 데이터가 많다면 사실상 모든 데이터를 전부 locking한 것과 동일하여 transaction의 병행성을 보장하지 못할 수 있습니다.
- 회피기법: 자원을 할당할 때 timestamp를 사용하여 deadlock가 일어나지 않도록 회피하는 방법입니다.
- 탐지/회복 기법: Transaction이 실행되기 전에는 아무런 검사를 하지 않고, deadlock이 발생하면 이를 감지하고 회복시키는 방법입니다.

[꼬꼬무 문답]
Q. deadlock을 해결하려면 어떻게 해야 하나요?
**[핵심 답변]**
각 transaction이 실행되기 전에 사용될 모든 데이터를 미리 locking을 해주는 예방기법이 있고, 자원 할당시 timestamp를 사용하여 deadlock이 발생하지 않도록 회피하는 기법이 있습니다. 또한 deadlock이 발생하면 이를 감지하고 회복시키는 탐지/회복기법이 있습니다.
Index
Q. Index가 왜 필요한가요?
[핵심 답변]
Index는 데이터베이스에서 table의 검색 성능을 높여주는 대표적인 방법중 하나입니다. 일반적인 RDBMS(관계형데이터베이스)에서는 B+Tree구조로 된 index를 사용하여 검색속도를 향상시킵니다.
index는 책마다 마지막 페이지에 있는 색인(index)과 같은 역할을 하는 자료구조입니다. 책에서 어떤 용어나 단어를 찾기위해 첫 페이지부터 끝 페이지 까지 전체를 훑지 않아도(Full Table Scan) index를 찾아보면 몇 페이지에 적혀 있는지 바로 찾을 수 있는 것(Index Scan)과 비슷합니다.
SELECT ~WHERE query를 통해 특정 조건을 만족하는 데이터를 찾을 때, full table scan할 필요 없이 정렬되어 있는 index에서 훨씬 빠른 속도로 검색을 할 수 있게 됩니다.
[면접
💡 Index는 개발자 면접 질문중에 가장 중요하고 자주 나오는 내용중에 하나 입니다. Index가 왜 필요하고 어느 상황에서 필요한지 묻는 질문을 받았을 때 index의 구조와 장단점을 알면 대답을 하기 수월합니다. 따라서 index의 원리와 어떤 역할을 하는지, 그리고 장단점과 구조는 어떻게 되는지에 초점을 맞춰서 학습해보도록 하겠습니다.
Index 구조
Index는 Btree, B+tree, Hash, Bitmap로 구현될 수 있습니다. 많은 데이터베이스 시스템에서 index는 B+tree구조를 가집니다. index를 생성하게 되면 특정 column(속성, attribute)의 값을 기준으로 정렬하여 데이터의 물리적 위치와 함께 별도 파일에 저장합니다. 이 때, Index에 저장되는 속성 값을 search-key값이라고 하고 실제 데이터의 물리적 위치를 저장한 값을 pointer라고 합니다. 즉, index는 순서대로 정렬된 search-key값과 pointer값만 저장하기 때문에 table보다 적은 공간을 차지합니다.
정리해보면 특정 column을 search-key 값으로 설정하여 index를 생성하면, 해당 search-key 값을 기준으로 정렬하여 (search-key, pointer)를 별도 파일에 저장합니다. 이를 index라고 합니다.
Index 사용하는 이유
Table에 데이터를 지속적으로 저장하게 되면 내부적으로 순서 없이 쌓이게 됩니다. 이 경우에 특정 조건을 만족하는 데이터를 찾고자 WHERE절을 사용한다면 Table의 row(record)를 처음부터 끝까지 모두 접근하여 검색조건과 일치하는지 비교하는 과정이 필요합니다. 이를 Full Table Scan이라고 합니다. 하지만 특정 coloumn에 대한 Index를 생성해 놓은 경우 해당 속성에 대하여 search-key가 정렬되어 저장되어 있기 때문에 조건 검색(SELECT ~ WHERE) 속도가 굉장히 빠릅니다.
클러스터형 인덱스와 보조 인덱스(clustering index & secondary index)
- clustering index: 특정 column을 기본키(primary key)로 지정하면 자동으로 클러스터형 인덱스가 생성되고, 해당 column 기준으로 정렬이 됩니다. Table 자체가 정렬된 하나의 index인 것입니다. 마치 영어사전처럼 책의 내용 자체가 정렬된 것을 떠올리면 쉽습니다.
- secondary index : 일반 책의 찾아보기와 같이 별도의 공간에 인덱스가 생성됩니다.
create index와 같이 index를 생성하기를 하거나 고유키(unique key)로 지정하면 보조 인덱스가 생성됩니다.




Index의 장단점
Index의 최대 장점은 검색 속도 향상 (SELECT~WHERE~ ) 입니다. 테이블을 만들고 안에 데이터가 쌓이게 되면 테이블의 record는 내부적으로 순서가 없이 뒤죽박죽으로 저장됩니다. 이렇게 되면 WHERE절을 통해 특정 조건에 맞는 데이터들을 찾아낼 때에도 reocrd의 처음부터 끝까지 다 읽어서 검색 조건과 맞는지 비교해야 합니다. 이것을 Full Table Scan이라고 합니다. 반면에 index를 생성하면 index에는 데이터들이 정렬되어 저장되어 있기 때문에 검색 조건에 일치하는 데이터들을 빠르게 찾아낼 수 있습니다. 이것이 Index를 사용하는 가장 큰 이유입니다.
Index의 단점으로는 크게 두 가지가 있습니다.
-
추가 저장공간 필요
index를 생성하면 index 자료구조를 위한 저장 공간이 추가적으로 필요합니다. 보통 table의 크기의 10%정도의 공간을 차지합니다.
-
느린 데이터 변경 작업
검색이 아닌 데이터 변경을 할 때, 즉 INSERT, UPDATE, DELETE가 자주 발생하면 성능이 나빠질 수 있습니다. 그 이유는 보통 B+tree구조의 index는 데이터가 추가 삭제 될 때마다 tree의 구조가 변경될 수 있기 때문입니다. 즉 인덱스의 재구성이 필요하기 때문에 추가적인 자원이 소모됩니다.
[꼬꼬무 문답]
Q. SELECT의 성능을 높일 수 있는 방법은 뭐가 있을까요?
**[핵심 답변]**
SELECT query의 성능을 높이는 가장 대표적인 방법중에 하나는 Index를 사용하는 것입니다. index를 사용하게 되면 SELECT WHERE절처럼 특정 조건을 만족하는 데이터를 검색할 때 table의 모든 데이터를 살펴볼 필요 없이 index에서 빠르게 해당 데이터에 접근할 수 있게 됩니다.
Q. index의 내부동작은 어떻게 동작하나요
**[핵심 답변]**
index는 대부분 B+Tree 자료구조로 이루어져 있어, WHERE 조건과 일치하는 데이터들의 저장위치를 훨씬 빠르게 찾을 수 있습니다.
Q. index를 많이 생성하면 안되나요?
**[핵심 답변]**
index를 생성하면 조건 검색 성능이 향상될 수 있습니다. 하지만 추가 저장공간이 필요하고, 데이터를 추가/수정/삭제를 할 때마다 관련 index를 모두 수정해줘야 되기 때문에 시간이 추가적으로 소요됩니다. 따라서 추가 저장공간과, 데이터 업데이트시 소요되는 추가 시간등을 복합적으로 고려하여 조건 검색의 성능향상이 더 큰 이득이 된다고 판단되는 column에만 index를 생성하는 것이 좋습니다.
Q. ⭐⭐⭐⭐ index를 어느 column에 사용하는 것이 좋을까요?
[핵심 답변]
index는 where 절에서 자주 조회되고, 수정 빈도가 낮으며, 카디널리티는 높고, 선택도가 낮은 column을 선택해서 설정하는 것이 가장 좋습니다.
| 기준 | 적합성 |
|---|---|
| 카디널리티(Cardinality) | 높을수록 적합 (데이터 중복이 적을수록 적합) |
| 선택도(Selectivity) | 낮을수록 적합 |
| 조회 활용도 | 높을수록 적합 (where 절에서 많이 사용되면 적합) |
| 수정 빈도 | 낮을수록 적합 |
[면접
💡 index를 어떤 column에 대해서 생성하는 것이 좋을지에대한 판단 근거를 물어보는 면접 질문입니다. DB 질문으로 거의 무조건 나오는 질문입니다. 굉장히 중요하지만 내용은 그렇게 어렵지 않으니 확실히 준비해서 꼬꼬무 질문에도 잘 답변하시길 바랍니다.
index를 사용하면 검색속도를 높이지만 추가 저장공간을 차지하고 데이터 업데이트시 속도가 느려지게 됩니다. 따라서 어떤 column에 index를 생성해야 하는지를 잘 학습하시기 바랍니다. 특히 몇 가지 예를 가져와서 이 경우에는 index 적용하는게 좋을까요? 안좋을까요? 라고 추가 질문을 종종 합니다. 꼬꼬무 질문을 참고해 주세요.
Index 효과적으로 사용하는 방법
-
SELECT WHERE절에 자주 사용되는 Column에 대해 index를 생성하는 것이 좋습니다.
-
데이터 수정 빈도가 낮을수록 적합합니다. insert / update / delete 작업 시, 데이터에 변화가 생기기 때문에 index에서는 매번 정렬을 다시 해야합니다. 이에 따른 부하가 발생하기 때문에 수정 빈도가 낮은 column을 index로 설정하면 좋습니다.
-
데이터의 중복이 높은 column은 index 효과가 별로 없습니다. 예를 들어 성별은 종류가 2 가지 밖에 없으므로 index를 생성하지 않는 것이 좋습니다. 즉, 선택도가 낮을 때 유리합니다.(보통 5~10% 이내)
-
데이터의 양이 많을 수록 index로 인한 성능향상이 더 큽니다. 데이터 양이 적다면 index의 혜택보단 손해가 더 클 수 있습니다.
-
Join 조건으로 자주 사용되는 column의 경우
-
한 table에 index가 너무 많은면 데이터 수정시 소요되는 시간이 너무 길어질 수 있습니다. (table당 4~5개 정도 권장)
[꼬꼬무 문답]
Q. index를 쓰면 성능이 좋아지니까 모든 컬럼에 인덱스를 사용하면 성능이 더 좋겠네요?
**[핵심 답변]**
그렇지 않습니다. 일단 index는 SELECT WHERE절에 대해서만 성능향상을 해줍니다. 이외에 데이터를 수정하게 되면 모든 index를 업데이트(+정렬)해야 하기 때문에 오히려 성능저하를 초래합니다. 또한 index를 생성할 때마다 저장공간도 차지하기 때문에 무분별하게 생성해서는 안됩니다.
Q. 우리 회사의 고객 DB에서 성별 column에 index를 걸어주는게 좋을까요?
**[핵심 답변]**
성별처럼 남녀 두 종류로만 나눠지는 경우에는 카디널리티가 매우 낮고, 선택도는 매우 높게 됩니다. 이 경우, index가 주는 이점이 매우 적고 오히려 저장공간 차지와 데이터 수정시 성능저하등을 고려하여 index를 생성하지 않는 것이 좋습니다.
Q. true 또는 false 값을 갖는 column에서, true 1%, false 99%의 비율로 구성된 상황에서는 index를 거는게 좋을까요?
**[핵심 답변]**
아무리 1%, 99%로 비율에 차이가 있어도, true / false 두 종류로만 나눠지는 경우에는 카디널리티가 매우 낮고, 선택도는 매우 높게 됩니다. 이 경우, index가 주는 이점이 매우 적고 오히려 저장공간 차지와 데이터 수정시 성능저하등을 고려하여 index를 생성하지 않는 것이 좋습니다.
Q. ⭐데이터를 검색을 할 때 hash table의 시간복잡도는 O(1)이고 b+tree는 O(logn)으로 더 느린데 왜 index는 hash table이 아니라 b+tree로 구현되나요?
[핵심 답변]
Hash table을 사용하면 하나의 데이터를 탐색하는 시간은 O(1)로 b+tree보 다 빠르지만, 값이 정렬되어 있지 않기 때문에 부등호를 사용하는 query에 대해서는 매우 비효율적이게 되어 데이터를 정렬해서 저장하는 b+tree를 이용합니다.
[면접 꿀TIP]
💡 하나의 값만 가져올 때는 hash table이 더 나을 수 있지만, 일정 범위의 값들을 찾을 때는 B+tree가 적합합니다. 이런 질문의 의도는, B+tree에 대해서 제대로 이해하고 있는지를 묻고 싶은 것입니다. 주로 B+tree로 구현되어 있는 index의 작동원리와 구조를 제대로 이해해 가시면 index에 대한 질문에는 더이상 막힐게 없습니다.
B+tree
[B+tree가 DB index를 위한 자료구조로 적합한 이유]
- 항상 정렬된 상태를 유지하여 부등호 연산에 유리합니다.
- 데이터 탐색뿐 아니라, 저장, 수정, 삭제에도 항상 O(logN)의 시간 복잡도를 갖습니다.



Hash index
hash index는 빠른 데이터 검색
4. 네트워크
TCP/IP
Q. OSI 7계층과 TCP/IP 4계층을 비교하여 설명해주세요.
[핵심 답변]
OSI 7계층은 네트워크 통신을 표준화한 모델로, 통신 시스템을 7단계로 나누어 설명한 것입니다.
하지만 OSI 모델이 실무적으로 이용하기에 복잡한 탓에 실제 인터넷에서는 이를 단순화한 TCP/IP 4계층이 사용되고 있습니다.
[면접
💡 저도 가끔 면접질문에서 받아봤던 네트워크의 가장 기초적인 내용입니다. 네트워크를 이해하기 위해서 필요한 기본적인 내용이면서 이해하기 어렵지 않으니 가벼운 마음으로 읽어보시길 추천합니다. OSI 7계층의 각 단계에서 어떤 동작이 일어나는지를 중점으로 공부하시면 됩니다. 또한 TCP/IP 4계층과의 차이점은 무엇인지를 비교하면서 공부하시면 충분합니다.
OSI 7계층과 TCP/IP 4계층
OSI 7계층과 TCP/IP 4계층 모델에서 각 계층은 하위 계층의 기능을 이용하고, 상위 계층에게 기능을 제공합니다. 예를 들어서 HTTP는 TCP과 IP을 이용해서 작동합니다.
일반적으로 상위 계층의 프로토콜은 소프트웨어로, 하위 계층의 프로토콜은 하드웨어로 구현됩니다.
(ex. 물리 계층의 통신은 케이블을 통한 전기 신호로 이루어집니다.)

캡슐화(Encapsulation) & 역캡슐화(Decapsulation)
캡슐화란 통신 프로토콜의 특성을 포함한 정보를 Header에 포함시켜서 하위 계층에 전송하는 것을 말합니다. 통신 상대측에서 이러한 Header를 역순으로 제거하면서 원래의 Data를 얻는 과정을 역캡슐화라고 합니다.
예를 들어, 사용자는 최상위 계층인 응용 계층에서 인터넷 접속(HTTP), 메일 전송(SMTP), 파일 전송(FTP), 원격 로그인(Telnet) 등의 작업을 수행합니다.

각 사용자입장에서 보면 data가 그냥 전송되는 것처럼 보이게 됩니다. 하지만 이 과정을 OSI 7계층 관점의 캡슐화 / 역캡슐화 과정까지 바라보면 다음과 같습니다.

사용자가 전송하고자 하는 데이터는 각 프로토콜의 정보를 Header에 포함시켜서 하위 계층에 전달하고**(Encapsulation)**, 이것은 최종적으로 물리 계층에서 binary 데이터로 변환되어 전송됩니다.
상대측에서는 이러한 Header를 역순으로 하나씩 제거하면서 상위 계층으로 데이터를 전달하고**(Decapsulation)**, 최종적으로 원본 데이터를 수신하게 됩니다.
TCP/IP 4계층? 5계층?
TCP/IP 4계층에서 시작한 네트워크 표준이 꾸준히 갱신되면서 하위 레이어가 다시 세분화 되었습니다. TCP/IP 4계층의 Network Interface Layer를 Data link Layer와 Physical Layer로 나뉘어져서 TCP/IP 5계층 모델이 되었습니다.
Q. ⭐ TCP vs UDP를 비교해서 설명해주세요
[핵심 답변]
TCP는 연결형, 신뢰성 전송 프로토콜 입니다. 연결지향적 서비스를 제공하기 위해 데이터를 전송하기 전에 3way handsaking을 하여 두 호스트의 전송 계층 사이에 논리적 연결을 설립합니다. 신뢰성 있는 서비스를 제공하기 위해 오류제어, 흐름제어, 혼잡제어 등을 실행합니다. 신뢰성을 보장하기 위해서 header가 더 크고 속도가 비교적 느리다는 단점이 있습니다.
UDP는 비연결형 프로토콜로 3-way handshake 등의 세션 수립 과정이 없습니다. 또한 비신뢰성 프로토콜로 흐름제어, 오류제어, 혼잡 제어를 제공하지 않습니다. 이러한 단순성 덕분에 적은 양의 오버헤드갖고 수신여부를 확인하지 않아서 속도가 빠릅니다
TCP는 신뢰성이 중요한 통신(HTTP, File 전송 등)에 쓰이고, UDP는 실시간성이 중요한 통신(동영상 스트리밍 등)에 주로 사용됩니다.
[면접
💡 TCP/UDP의 차이점을 묻는 질문이 종종 나옵니다. 특히 네트워크 관련 회사와 통신이 중요한 회사의 경우에는 자주 나오는 질문중 하나 입니다.
깊은 내용까지 잘 파고들지 않기 때문에 TCP/UDP 각각의 장점, 단점 그리고 활용 정도에 주안점을 두고 공부하시면 충분히 답변하실 수 있습니다.
TCP/IP 전송계층
TCP/IP는 인터넷에서 사용하는 프로토콜 그룹을 칭합니다. TCP/IP는 Application layer(응용계층), Transport layer(전송계층), Network layer, Data link layer, Physical layer로 5개의 계층으로 나뉩니다.
그 중에 전송계층은 두 응용 계층 사이에서의 process-to-process 통신을 제공합니다. 전송계층은 응용계층으로부터 메시지를 받아 전송계층 패킷으로 캡슐화하여 전송합니다.(segment 또는 datagram으로 부릅니다.)
전송계층의 주된 프로토콜은 TCP, UDP입니다. TCP(Transmission Control Protocol)는 연결형, 신뢰성 전송 프로토콜입니다. TCP로 전송하는 패킷을 segment라고 부릅니다. UDP(User, Datagram Protocol)는 비연결형, 비신뢰성 전송 프로토콜입니다. UDP로 전송하는 패킷을 datagram이라고 합니다.

TCP(Transfer Control Protocol)
TCP는 연결형, 신뢰성 전송 프로토콜입니다.
연결지향적 서비스를 제공하기 위해 데이터를 전송하기 전에 먼저 두 호스트의 전송 계층 사이에 논리적 연결을 설립합니다. 그 후 데이터 전송을 하고 데이터 전송을 완료했으면 연결을 해제합니다. TCP의 통신은 이렇게 connection setup, data transfer, connection termination의 세 단계로 나뉩니다.
신뢰성 있는 서비스를 제공하기 위해 TCP가 전체 스트림을 순서에 맞고 오류 없이, 또한 부분적인 손실이나 중복 없이 전송하는 것을 보장합니다. 이를 가능하게 하는 방법은 오류제어, 흐름제어, 혼잡제어 등이 있습니다. 흐름제어는 데이터를 보내는 속도와 데이터를 받는 속도의 균형을 맞추는 것을 뜻합니다. 오류제어는 훼손된 segment의 감지 및 재전송, 손실된 segment의 재전송, 순서가 맞지 않게 도착한 segment를 정렬하고 중복 segment 감지 및 폐기를 합니다. 이는 TCP header의 checksum, 확인응답, 타임-아웃 등을 통해 수행됩니다.


UDP(User Datagram Protocol)
UDP는 비연결형, 비신뢰성 전송 프로토콜입니다.
UDP는 논리적 연결을 설립하지 않고 datagram을 전송하는 비연결형 프로토콜입니다. 또한 흐름제어, 오류제어, 혼잡 제어를 제공하지 않는 간단한 프로토콜입니다. 이러한 단순성은 적은 양의 오버헤드갖기 때문에 작은 메시지를 보내거나 신뢰성을 크게 고려하지 않아도 되는 상황에서 사용합니다.
ex) 매우 큰 문서파일을 인터넷을 통해 다운받고 있다고 가정해 봅시다. 이 경우엔 신뢰성이 보장되는 프로토콜을 사용해야 합니다. 다운로드 완료된 파일의 일부분이 손실되거나 훼손되어 있으면 안되기 때문입니다. 문서 파일 전송시에 발생하는 지연은 중요한 문제가 아닙니다. 따라서 UDP를 사용하면 안되고 TCP를 사용해야 합니다.
ex) live방송과 같이 실시간 상호작용을 하는 응용프로그램을 사용한다고 가정해 봅시다. 음성과 영상을 한프레임씩 전송을 합니다. 전송계층에서 훼손되거나 손실된 프레임을 재전송 해야된다면 전체적으로 지연이 될겁니다. 따라서 UDP를 통해서 한프레임씩 datagram으로 전송한다면 훼손되거나 손실된 패킷은 그냥 무시하고 나머지 패킷을 응용프로그램으로 전달한다. 손실된 패킷으로 인해 짧은 시간동안 화면의 일부분이 공백으로 표시되더라도 대부분의 시청자들은 인식하지 못합니다. 이 때는 신뢰성보다 실시간성이 더 중요하기때문에 UDP를 사용합니다.


Q. 3-way handshake는 무엇이고 각 과정은 어떻게 되나요?
[핵심 답변]
3-way handshake는 TCP/IP 프로토콜로 통신하기 전, 정확한 정보 전송을 위해 상대방 컴퓨터와 세션을 수립하는(연결을 하는) 과정입니다. (TCP 연결 초기화)
클라이언트가 서버에게 접속을 요청하는 SYN 패킷을 보내면, 서버는 요청을 수락하는 ACK를 포함하여 SYN+ACK 패킷을 클라이언트에게 발송합니다. 클라이언트가 이것을 수신한 후, 다시 ACK를 서버에게 발송하면 연결이 이루어지고, 이로써 데이터를 주고받을 수 있게됩니다.
[면접
💡 저의 첫 면접인 S전자 무선사업부 Software직군 지원 당시의 첫 질문이었습니다. 그래서 기억이 많이 납니다. 컴퓨터공학 전공생이라면 무조건 알 수 밖에 없는 내용이였기 때문에 기본을 잘 알고 있는지 물어보고자 했던 것 같습니다.
자주 나오진 않지만 아주 기초적인 네트워크 지식이기 때문에 꼭 알고 넘어가야 하는 내용입니다. HTTP 1.1 과 2.0 버전은 모두 TCP프로토콜을 사용합니다. 그래서 우리가 네이버에 접속할 때마다 네이버의 서버와 나의 노트북이 3-way handshake를 하면서 서로를 확인하게 됩니다.
면접에서는 3-way handshake를 하는 목적은 무엇인지, 각 step의 절차는 어떻게 되는지를 중점적으로 보시면 됩니다. 4-way handshake는 가벼운 마음으로 읽어보시면 충분합니다.
TCP 3 way handshake
TCP 통신은 아래와 같은 3단계의 과정을 거칩니다.
- Connection setup (tcp 연결 초기화) - 3way handshaking
- Data transfer (데이터 전송)
- Connection termination (tcp 연결 종료) - 4way handshaking
우리가 공부한 3-way handshaking이 바로 Connection setup의 과정입니다.

4 way handshaking
3-way handshake를 통해 Connection setup을 했다면 tcp 연결을 종료하는 Connection termination 과정은 4-way handshaking을 통해 이루어집니다.
TCP connection termination은 양방향으로 2개의 연결이 독립적으로 닫히기 때문에 4-way 단계를 밟게 됩니다.
- Client process에서 active close를 하면, client tcp에서 FIN 세그먼트를 보냅니다.
- Server는 FIN 세그먼트를 받았다는 응답에 대한 ACK를 client로 보냅니다. 이때, server 내의 process에게 EOF를 보내지만, 아직 process는 close되지 않을 수 있습니다.
- Server process로부터 passive close를 받으면 server tcp에서 FIN 세그먼트를 client TCP에게 보냅니다.
- Server tcp가 ACK를 받게 되면 연결이 종료됩니다.

[꼬꼬무 문답]
Q. 그럼 4-way handshake는 뭔가요?
**[핵심 답변]**
3-way handshake를 통해 Connection setup을 했다면 **tcp 연결을 종료**하는 **Connection termination** 과정은 **4-way handshaking**을 통해 이루어집니다.
TCP connection termination은 양방향으로 2개의 연결이 독립적으로 닫히기 때문에 4-way 단계를 밟게 됩니다.
HTTP
Q. HTTP가 뭔지 설명해 주세요.
[핵심 답변]
HTTP는 HyperText Transfer Protocol의 약자로 서버-클라이언트 모델을 따르면서 request/response 구조로 웹 상에서 정보를 주고받을 수 있는 프로토콜입니다. TCP/IP 기반으로 작동하며, HTTP의 가장 큰 특징은 Connectionless와 Stateless 입니다.
[면접
💡 광범위한 질문이라 더 대답하기 어려울 수 있어요. 간혹 HTTP가 어떤 용어의 약자인지 물어보기도 하고, 구성요소를 묻기도 하고, 특징들을 물어보기도 합니다. HTTP는 웹개발자에게 특히 중요하기 때문에 기본적인 구조와 특징은 꼭 알아두시기 바랍니다.
HTTP
HTTP는 HyperText Transfer Protocol의 약자로 웹 상에서 정보를 전송하기 위한 통신 프로토콜로써 HTML과 같은 문서를 전송하는 것에 사용됩니다.
클라이언트가 HTTP repuest를 서버에 보내면 서버는 HTTP response 를 클라이언트에 보내는 구조입니다. request message는 start line(method, path, HTTP version), headers, body로 이루어져 있고 response message는 status line(HTTP version, status code, status message), headers, body로 이루어져 있습니다.
HTTP는 서버에 연결 후 요청에 응답을 받으면 연결을 끊어버리는 Connectionless 특성을 갖습니다. 이로 인해 많은 사람이 웹을 이용하더라도 실제 동시 접속을 최소화하여 더 많은 유저의 요청을 처리할 수 있습니다. 하지만 연결을 끊었기 때문에, 클라이언트의 이전 상태(로그인 유무 등)를 알 수가 없다는 Stateless 특성이 생기게 됩니다. 정보를 유지할 수 없는 Connectionless, Stateless 특성을 가진 HTTP의 단점을 해결하기 위해, cookie, session, jwt 등이 도입되었습니다.
또한 HTTP는 정보를 text 형식으로 주고받기 때문에 중간에 인터셉트할 경우 데이터 유출이 발생할 수 있는 문제가 있어서 이를 해결하고자 HTTP에 암호화를 추가한 프로토콜이 바로 HTTPS입니다.


Q. ⭐⭐ HTTP resquest method 중 GET vs POST를 비교 설명해 주세요.
[핵심 답변]
GET 메소드는 클라이언트가 서버에게 리소스를 요청할 때 사용하는 메소드이고, POST 메소드는 서버에게 데이터 처리(주로 생성)를 요청할 때 사용하는 메소드입니다.
GET 요청의 경우 필요한 정보를 특정하기 위해 URL 뒤에 Query String을 추가하여 정보를 조회하고, POST 요청의 경우 전달할 데이터를 Body 부분에 포함하여 통신합니다.
GET 요청의 경우 URL 뒤의 Query String까지 포함해서 브라우저 히스토리에 남게 되고 캐시가 가능하지만, POST 요청의 경우 브라우저 히스토리에 남지 않고 캐시도 불가능합니다.
[면접
💡 HTTP method를 묻는 면접 질문은 굉장히 자주 나옵니다. 특히 GET과 POST를 비교하는 질문이 가장 자주 나옵니다. 해당 유형의 문제의 경우 GET과 POST의 차이점을 중심으로 공부를 해두시는게 좋습니다. 중요한 차이점은 전달할 데이터를 어디에 포함시켜서 전송하는지, 이 차이점으로 인하여 캐시가능 여부, 보안 그리고 용도도 달라지겠죠.
GET, POST 뿐 아니라 PATCH, PUT도 면접에서 종종 물어봅니다. 이 질문을 처음 받았을 때, 저는 대비가 안된 상태라 대답을 전혀 하지 못했어요. 개인 프로젝트를 할 때 GET과 POST는 굉장히 자주 사용해서 잘 알고 있었지만, PUT과 PATCH는 잘 사용하지 않았고 원칙없이 사용했었거든요. 두 method 모두 서버의 리소스를 수정한다는 점에서 비슷한 것 같지만 큰 차이가 있습니다. PUT은 모든 리소스! PATCH는 일부 리소스!
이런 내용을 중심으로 답변을 잘 준비해보도록 해요!
Method
- GET : 리소스 조회
GET method는 클라이언트가 서버에게 정보를 요청할 때 사용하는 method 입니다. GET을 통한 요청은 URL 주소 끝에 key-value 쌍으로 parameter를 포함하여 전송을 하는데, 이 부분을 Query String을 이라고 부릅니다.
GET의 주요한 특징중 하나는 캐시가 가능하다는 것입니다. 한 번 서버에 GET요청을 한적이 있다면 브라우저가 그 결과를 저장해 둡니다. 이후 동일한 요청은 브라우저에 저장된 값으로 가져올 수 있습니다.

- POST : 요청 데이터 처리 (주로 생성)
POST method는 클라이언트가 body를 통해 전달한 데이터를 서버가 처리하도록 요청하는 method 입니다. 서버는 POST 메시지를 받으면 꼭 리소스를 등록하는 것만 아니라, 리소스마다 다양하게 처리를 합니다. 데이터를 생성하거나 변경하기도 하지만 특정 프로세스를 처리하기도 합니다.
- PUT : 리소스를 대체, 해당 리소스가 없으면 생성
- PATCH : 리소스의 일부분을 수정
ex)
// Server resource
// Before
user/10
{
name: Noname,
language: C++
}
// Request
PUT user/10
{
name: Nossi,
}
// After
user/10
{
name: Nossi,
}
// Server resource
// Before
user/10
{
name: Noname,
language: C++
}
// Request
PATCH user/10
{
name: Nossi
}
// After
PATCH user/10
{
name: Nossi,
language: C++
}
[꼬꼬무 문답]
Q. HTTP resquest method중 Put vs Patch을 비교 설명해주세요.
**[핵심 답변]**
PUT 메소드와 PATCH 메소드는 모두 서버의 리소스를 업데이트하는 메소드라는 공통점이 있습니다. 하지만 PUT 요청의 경우 모든 리소스를 수정,대체하고, PATCH 요청의 경우 일부 리소스만 수정하게 됩니다.
Q. HTTP status code에 대해서 설명해 주세요
[핵심 답변]
HTTP status code는 클라이언트가 보낸 HTTP 요청에 대한 서버의 응답 코드로, 상태 코드를 통해 요청의 성공/실패 여부를 판단할 수 있습니다. 100번대부터 500번대까지 총 5개의 클래스로 구분되어 HTTP 요청에 대한 상태를 알려줍니다.
[면접
💡 종종 나오는 면접질문 중에 하나 입니다. status code무엇인지, 알고있는 status code를 모두 설명해 달라는 질문도 하곤 합니다. 자주 사용하는 대표적인 status code만 외워가도 충분한 답을 할 수 있습니다. (200, 201, 400, 401, 403, 404, 500)
Status code
웹 개발시 서버와 클라이언트가 HTTP 통신할 때 주고받아야 할 값중에 하나입니다. 클라이언트로 부터 받은 request에 대한 서버의 response에 대한 간략할 설명 이라고 볼 수 있습니다. 상황에 알맞는 status code를 response에 담아서 클라이언트에 넘겨주면 이를 토대로 클라이언트는 알맞는 대응을 할 수 있습니다.
모든 HTTP status code는 5개의 클래스로 구분됩니다.
- 1xx (정보): 요청을 받았으며 작업을 계속한다.
- 2xx (성공): 클라이언트가 요청한 동작을 성공적으로 수신하여 이해했고 성공적으로 처리하였다.
- 3xx (리다이렉션): 요청을 완료하기 위해 추가 작업 조치가 필요하다.
- 4xx (클라이언트 오류): 클라이언트의 요청에 문제가 있다.
- 5xx (서버 오류): 서버가 유효한 요청의 수행을 실패했다.
[참고] 자주 등장하는 HTTP 응답코드
| status code | message | |
|---|---|---|
| 200 | OK | 요청이 성공함 (ex. 잔액조회 성공) |
| 201 | Created | 리소스 생성 성공 (ex. 게시글 작성 성공, 회원가입 성공) |
| 400 | Bad Request | 데이터의 형식이 올바르지 않는 등 서버가 요청을 이해할 수 없음 |
| (ex. 올바르지 않은 형식의 데이터 입력 등) | ||
| 401 | Unauthorized | 인증되지 않은 상태에서 인증이 필요한 리소스에 접근함 |
| (ex. 로그인 전에 사용자 정보 요청 등) | ||
| 403 | Forbidden | 인증된 상태에서 권한이 없는 리소스에 접근함 |
| (ex. 일반 유저가 관리자 메뉴 접근 등) | ||
| 404 | Not Found | 요청한 route가 없음. 찾는 리소스가 없음 |
| (ex. www.naver.com/nossi 등 존재하지 않는 route에 요청 등) | ||
| 500 | Bad Gateway | 서버에서 예상하지 못한 에러가 발생함 |
| (ex. 예외처리를 하지 않은 오류가 발생 등) |
Q. ⭐⭐ www.google.com을 주소창에 쳤을 때 화면이 나오기까지의 과정을 네트워크 관점으로 설명해 주세요.
[핵심 답변]
- 사용자가 브라우저에 URL 입력
- 브라우저는 DNS를 통해 서버의 IP 주소를 찾는다
- client에서 HTTP request 메시지 ⇒ TCP/IP 패킷 생성 ⇒ server로 전송
- server에서 HTTP requset에 대한 HTTP response 메시지 ⇒ TCP/IP 패킷 생성 ⇒ client로 전송
- 도착한 HTTP responsse message는 웹 브라우저에 의해 출력(렌더링)
[면접
💡 굉장히 자주 나오는 면접 질문중에 하나입니다. 이 질문을 통해서 면접관 입장에서는 지원자가 웹 개발 전반적인 프로세스에 대해서 잘 이해하고 있는지를 다각적으로 판단할 수 있어서 좋습니다. 특히 해당 질문은 frontend 관점에서 집중적으로 물어볼 수 있고, backend 관점에서 깊게 물어볼 수 있습니다. 별다른 언급이 없다면 네트워크 관점에서 절차에 따라 설명하면 충분한 답변을 할 수 있습니다. 이번 강의에서는 network 관점에서 답변을 구성해 보았습니다.
사용자가 입력한 URL이 어떻게 IP로 변환되는지, request 메세지가 전달되는 절차와 앞서 살펴본 HTTP protocol,과 TCP protocol을 거쳐서 패킷이 되는 과정, request 메세지를 받은 서버에서는 HTTP response message를 구성하여 client로 전송하는 것 등을 절차에 맞게 순차적으로 설명하면 됩니다.
웹 동작 방식
- 유저가 브라우저에서 www.google.com(URL)을 입력을 하면 HTTP request message를 생성합니다.
- IP주소를 알아야 전송을 할 수 있으므로, DNS lookup을 통해 해당 domain의 server IP주소를 알아냅니다.
- 반환된 IP주소(구글의 server IP)로 HTTP 요청 메시지(request message) 전송 요청을 합니다.
- 생성된 HTTP 요청 메시지를 TCP/IP층에 전달합니다.
- HTTP 요청 메시지에 헤더를 추가해서 TCP/IP 패킷을 생성합니다.
- 해당 패킷은 전기신호로 랜선을 통해 네트워크로 전송되고, 목적지 IP에 도달합니다.
- 구글 server에 도착한 패킷은 unpacking을 통해 message를 복원하고 server의 process로 보냅니다.
- server의 process는 HTTP 요청 메시지에 대한 response data를 가지고 HTTP 응답 메시지(response message)를 생성 합니다.
- HTTP 응답 메시지를 전달 받은 방식 그대로 client IP로 전송을 합니다.
- HTTP response 메시지에 담긴 데이터를 토대로 웹브라우저에서 HTML 렌더링을 하여 모니터에 검색창이 보여집니다.

Authorization
Q. ⭐쿠키와 세션의 차이점을 설명해 주세요
[면접
💡 쿠키와 세션의 각각 특징들을 제대로 이해해야 차이점을 말할 수 있습니다. 특히 저장 위치의 차이와 이에 따른 보안성, 부하에 대해 설명하면 가장 좋습니다.
connectionless, stateless
쿠키와 세션을 사용하는 이유는 HTTP의 connectionless(비연결성), stateless(비상태성)라는 특징 때문입니다. 클라이언트가 요청(request)을 했을 때 그 요청에 맞는 응답(response)을 보낸 후 연결을 끊고, 서버는 클라이언트에 대한 상태 정보를 유지하지 않기 때문에 알 수 없게 됩니다.
만약 쿠키와 세션을 사용하지 않는다면 인프런에 로그인을 했음에도 페이지를 이동할 때마다 계속 로그인을 해야됩니다. 또한 로그인을 할때, 아이디 비밀번호 저장을 하여 다음번에 재방문 할 때에도 해당 아이디와 비밀번호를 자동으로 입력하도록 할 수 있습니다. 이 외에도 쇼핑몰의 장바구니 기능과 팝업에서 “오늘 더이상 이 창을 보지 않음" 등의 편의성을 제공할 수 있게 됩니다.
쿠키(cookie)
쿠키의 생성과 저장은 구현에 따라 다르지만 원리는 동일합니다.
- 서버가 클라이언트로부터 요청을 받았을 때, 클라이언트에 관한 정보를 토대로 쿠키를 구성합니다.
- 서버는 클라이언트에게 보내는 응답의 header에 쿠키를 담아 보냅니다.
- 클라이언트가 응답을 받으면, 브라우저는 쿠키를 쿠키 디렉터리에 저장합니다.
쿠키는 클라이언트(브라우저) key-value 쌍으로 로컬에 저장되는 데이터 파일입니다. 유효시간 내에서는 브라우저가 종료되어도 계속 유지됩니다. 서버에서 response header에 set-cookie속성을 사용해서 클라이언트에 쿠키를 만들고, 사용자가 따로 작업을 하지 않아도 브라우저가 쿠키를 request header에 담아서 서버에 전송합니다.

세션(session)
세션은 기본적으로 쿠키를 이용하여 구현이 됩니다. 클라이언트를 구분하기 위해 각 클라이언트에게 session ID를 부여하고 클라이언트는 쿠키에 session ID를 저장해 둡니다. 사용자 정보를 브라우저에 저장하는 쿠키와 달리 세션은 서버측에 저장하여 관리합니다. 세션은 유효시간을 두어 일정 시간 응답이 없다면 끊을 수 있고, 브라우저가 종료될 때까지 인증상태를 유지할 수 있습니다. 사용자 정보를 서버에 두기 때문에 쿠키보다 보안은 좋지만 서버 자원을 차지하기 때문에 서버에 과부하를 줄 수 있고 성능 저하의 요인이 될 수 있습니다.

[핵심 답변]
쿠키는 클라이언트(브라우저) 로컬에 key-value 쌍으로 저장되는 데이터 파일입니다. 유효시간 내에서는 브라우저가 종료되어도 계속 유지됩니다.
세션은 브라우저가 종료되거나, 서버에서 해당 세션을 삭제할 수 있기 때문에 쿠키보다 보안성이 좋습니다. 또한 서버에 데이터를 저장하므로 서버 용량이 허용하는 한에서 제한 없이 데이터를 저장할 수 있다는 장점이 있지만 서버의 부하가 커진다는 단점이 될 수 있습니다.
[꼬꼬무 문답]
Q. 세션이 보안도 좋은데 쿠키를 사용하는 이유는 뭔가요?
**[핵심 답변]**
세션은 서버의 자원을 사용하기 때문에 서버가 느려질 수 있고 서버 자원이 부족할 수 있습니다. 따라서 쿠키를 사용하면 서버 자원의 낭비를 방지하여 웹사이트 속도를 높일 수 있습니다.
Q. 쿠키의 사용 예를 아는대로 말씀해주세요
**[핵심 답변]**
1. 쇼핑몰의 장바구니 기능
2. 로그인시 아이디와 비밀번호 저장(또는 자동로그인)
3. 팝업에서 “오늘 더 이상 이 창을 보지 않음” 체크
Q. 쿠키와 세션을 이용한 로그인 방식을 화이트보드에 설명해 주세요.
[면접
💡 로그인에 대한 내용은 웹개발자라면 굉장히 자주 물어보는 질문이기 때문에 잘 이해해 두시는게 좋습니다.
HTTP는 비연결성, 비상태성의 특성을 지니기 때문에 서버는 클라이언트가 로그인을 했더라도 이후 요청 때 해당 클라이언트가 로그인을 했었는지 알 수 없습니다. 하지만 쿠키와 세션을 활용한다면 로그인 상태를 유지할 수 있게 됩니다.
쿠키와 세션을 이용하여 어떤 절차로 로그인이 되고 상태가 저장되는지 이해하시고 설명하실 수 있다면 질문에 대한 충분히 좋은 답을 하실 수 있습니다.
쿠키와 세션을 통한 인증(authentication)과 인가(authorization)
인증(authentication)은 사용자가 누구인지 확인하는 절차입니다. 회원가입과 로그인 과정이 인증의 대표적인 예시입니다. 인가(authorization)는 사용자가 요청하는 것에 대한 권한이 있는지를 확인하는 절차입니다.
세션을 통한 인증, 인가(auth)의 절차는 다음과 같습니다.
- 클라이언트가 로그인을 하면 서버는 회원정보를 대조하여 인증을 합니다.(authentication)
- 회원 정보(클라이언트 정보)를 세션저장소에 생성하고 session ID를 발급합니다.
- http response header 쿠키에 발급한 session ID를 담아서 보냅니다.
- 클라이언트에서는 session ID를 쿠키 저장소에 저장하고 이후에 http request를 보낼 때마다 쿠키에 session ID를 담아서 보냅니다.
- 서버에서는 쿠키에 담겨져서 온 session ID에 해당하는 회원 정보를 세션 저장소에서 가져옵니다.(authorization)
- 응답 메시지에 회원 정보를 바탕으로 처리된 데이터를 담아서 클라이언트에 보냅니다.
사용자가 로그인을 하면 서버는 session ID를 쿠키로 클라이언트에게 보냅니다. 클라이언트는 session ID를 요청시마다 헤더에 담아서 보내면 서버는 session ID에 해당하는 클라이언트 정보를 세션저장소에서 가져옵니다. 이를 통해 클라이언트 정보에 따라 맞춤 응답을 할 수 있게 됩니다. 하지만 서버에서 세션저장소를 사용하여 사용자 데이터를 저장해야 되기 때문에 추가적인 저장공간을 필요로 합니다.
session ID만 쿠키에 담겨서 요청을 보내기 때문에 요청 때마다 사용자 정보를 쿠키에 담아서 전송하는 것보다 안전합니다. 하지만 session ID만 노출되어 악의를 가진 다른 사용자가 이를 이용해 서버에 요청하면 서버는 구별해낼 수 있는 방법이 없습니다. 이를 Session hijacking 이라고 합니다. 해결책으로는 HTTPS 를 사용하거나 session에 짧은 주기로 만료시간을 설정하는 방법이 있습니다.
또한 세션과 쿠키를 이용한 로그인 방식은 Load Balancing 및 서버 효율성 관리 및 확장이 어려워질 수 있다는 단점이 있습니다.
[핵심 답변]

모의면접 1
- 자기소개를 1분정도 간단히 해주세요.
- 개발자를 하게 된 이유가 뭘까요?
- 개발 관련 공부는 어떤 방식으로 하시나요?
- 저희 회사에서 지원자님을 뽑아야 하는 이유를 어필해주실 수 있나요?
- hash table이 뭔지 설명해주실 수 있나요?
- hash table에서 hash value가 충돌하는 경우에는 어떻게 해결해야 할까요?
- open addressing방식으로 해결한다고 하셨는데, 이 경우 데이터 삭제를 할 때 어떤 문제점이 생길 수 있을까요?
- double hashing이 뭔지 설명해주실 수 있나요?
- http의 get과 post의 차이점을 말씀해주세요.
- patch과 put의 차이점을 말씀해주세요
- 삽입정렬에 대해서 설명해 주세요.
- 정렬중에서 가장 빠른 정렬이 어떤 정렬일까요?
- 퀵정렬에 대해서 설명해 주세요.
- 선택 정렬에 대해서 설명해 주세요.
- DB사용되는 Transaction에 대해서 간단하게 설명해주시겠어요
- transaction의 무결성을 유지하기 위한 특징을 아는대로 말씀해주세요.
- Deadlock을 간단히 설명해주세요.
- Deadlock을 해결하는 방법은 뭐가 있을까요?
- 지원자님께서 저희에게 물어볼 것이 있거나, 못다한 말이 있다면 간단히 해주세요
모의면접 2
- 자기소개를 1분정도 간단히 해주세요.
- 수행해야 되는 프로젝트가 굉장히 어려운 주제인데, 혼자서는 해결 못할 것 같으면 어떻게 하시겠나요?
- 팀프로젝트를 하실 때 주로 어떤 역할을 담당하셨나요? 매니저 또는 팀원 충돌 조율 같은 역할이요
- 팀을 구성할 때, 처음에는 맘에 들어서 팀원을 받아들였는데, 같이 일하다보니까 멀어진 경우가 있나요? 아니면 처음에 마음에는 쏙 들지 않았지만 일하다 보니 맘에 들었던 상황이 있나요?
- 멀티쓰레드와 멀티 프로세스를 비교 설명해 주세요
- multi process/thread 환경에서 발생하는 동기화 문제에 대해서 아시나요?
- 동기화문제를 어떻게 해결하면 좋을까요?
- mutex와 semaphore 차이점을 중심으로 설명해 주세요.
- heap 자료구조에 대해서 아시나요
- heap을 구현하기 이해서 array 와 linked list중에 어떤 것을 이용하면 좋을까요?
- heap의 push()와 pop() operation의 시간복잡도는 어떻게 될까요
- heap의 pop()을 하면 root node를 제거하게 되죠. 그 다음 동작은 어떻게 되나요?
- 이진 탐색 트리에서 저장된 정보가 256개 일 때, 탐색횟수는 몇번일까요?
- 탐색의 시간복잡도를 O(logN)으로 가정하신 것 같은데, 최악의 경우에는 시간복잡도가 어떻게 될까요?
- 어떤 상황에 탐색의 시간복잡도가 O(n)이 되나요?
- 이를 해결하기 위한 방법을 아시는게 있으신가요
- RDB에서 index가 왜 필요할까요?
- index를 사용하면 검색속도가 빨라진다고 하셨는데, 그럼 모든 column에 index를 생성하면 좋곘네요? 어떻게 생각하세요
- 성별 column에 남자 2% 여자98% 비율로 데이터가 있을 때, index를 생성하는게 좋을까요?
- MySQL에서는 index의 자료구조로 B+Tree를 주로 사용하는데, B+Tree의 검색 시간 복잡도는 어떻게 되나요?
- Hash index는 검색 시간이 O(1)인데, 왜 B+Tree를 사용하는거죠?
- 지원자님께서 저희에게 물어볼 것이 있거나, 못다한 말이 있다면 간단히 해주세요
모의면접 3
- 3분정도 시간을 드릴테니 편안하게 자기소개를 해주세요.
- 왜 백엔드(또는 그 외 포지션)를 선택하셨나요?
- 백엔드(또는 그 외의 포지션)로 지원하셨는데, 다른 역할이 주어진다면 입사할 생각이 있으신가요?
- 본인의 성격 장단점을 말씀해주세요
- Linked list에 대해서 간단히 설명해 주세요.
- Linked list와 Array를 비교해서 설명해주세요.
- 어느 상황에 Array보단 Linked list를 쓰는게 좋을까요.
- Dynamic array에 대해서 간단히 설명해 주세요.
- 웹서비스에서 REST API의 특성에 대해서 갖추야 하는 조건을 생각나는 대로 말씀해주시겠어요?
- REST API가 왜 이런 특성들을 갖춰야하나요? 무슨 장점이 있길래,
- 그럼 모든 웹 API들이 RESTful하게 만들면 좋겠네요?
- 가상 메모리에 대해서 간단히 설명해 주세요
- page와 segmentation를 간단히 비교 설명해 주세요.
- 알고계신 page 교체 알고리즘이 어떤게 있나요?
- LRU알고리즘과 LFU 알고리즘을 간단히 비교 설명해 주세요.
- NoSQL을 프로젝트에서 사용해보신 적 있으신가요?
- NoSQL의 장점이 어떤게 있을까요?
- RDB의 장점은 어떤게 있을까요?
- 지원자님께서 저희에게 물어볼 것이 있거나, 못다한 말이 있다면 간단히 해주세요
모의면접 4
- 자기소개를 1분정도 간단히 해주세요.
- 언제부터 개발을 하셨나요? 개발 공부를 시작하시게 된 계기가 있을까요?
- 지원자님만의 개발 공부 방법이 있을까요?
- 컴퓨터 공부를 하면서 어려움은 없었나요? 있었다면 어떻게 극복하셨나요
- 지원자님만의 스트레스 해소법이 있으신가요?
- hash table의 검색 시간복잡도는 어떻게 되나요?
- 검색의 worst case의 경우 O(n)이라고 말씀해 주셨는데, 더 자세히 설명해주시겠어요?
- hash table에서 hash value가 충돌하는 경우에는 어떻게 해결해야 할까요?
- seperate chaining에 대해서 자세히 설명해 주세요.
- RDB에서 사용되는 JOIN의 종류 아는대로 말씀해주세요
- inner join은 어떤 join인가요
- left join은 어떤 join인가요?
- www.google.com을 주소창에 쳤을 때 화면이 나오기까지의 과정을 설명해 주세요.
- TCP와 UDP를 비교해서 설명해 주세요.
- 쿠키와 세션을 비교해서 설명해 주세요.
- 지원자님께서 저희에게 물어볼 것이 있거나, 못다한 말이 있다면 간단히 해주세요
Process vs Thread
Process(작업)은 최소 1개의 Thread 존재
OS는 Virtual Memory를 Process에게 할당 → Virtual Memory는 Process로 제한된 공간
따라서 Process에 속한 모든 Thread는 Process의 Virtual Memory로 공간이 제약된다.
Thread는 실질적으로 연산을 하는 주체다.
- Multi Threading → 동시성 → 동기화 이슈
- Thread마다 각자 Thread Local Storage를 가짐
- 공통의 공간인 Heap 존재함

객체 지향 설계의 5가지 원칙 - SOLID
-
SRP - 단일 책임 원칙
- 한 클래스는 하나의 책임만 가져야한다.
- 단일 책임 원칙에서 중요한 기준은 변경이다. 변경이 있을 때, 파급 효과가 적으면 단일 책임 원칙을 잘 따른 것이다. 객체 생성과 사용을 분리한다면 파급 효과가 적도록 설계할 수 있다.
- 스프링에서 이용한다면 구현 객체를 생성해 객체를 생성하고 역할을 명시한 인터페이스를 사용하도록 하는 것이다.
-
OCP - 개발
- SW 요소의 확장에는 열려 있으나 변경에는 닫혀있어야한다.
- 새로운 기능을 구현하는 객체를 만들기 위해서는 인터페이스를 상속받는 새로운 클래스를 하나 만들어 구현하게 만든다. 역할과 구현의 분리를 통해 확장에는 열려 있게하고, 변경에는 닫혀 있게 만들 수 있다. 하지만 구현 객체를 변경하려면 클라이언트 코드를 변경해야 하고, 다형성 원칙으로 OCP 원칙을 전부 지킬 수 없다.
- 스프링에 원래 생성되어 있는 기능들의 변경을 하지 않고, 새로운 객체를 생성함으로써 확장에는 자유로워야 한다. 다형성의 원칙으로는 OCP원칙을 다 지킬 수 없는 부분은 스프링의 DI와 DI 컨테이너를 이용해 단점을 보완할 수 있다.
-
LSP - 리스코프 치환 원칙
- 프로그램 객체는 프로그램의 정확성을 깨뜨리지 않으면서 하위 타입의 인스턴스로 바꿀 수 있어야 한다.
- 다형성에서 하위 클래스는 인터페이스 규약을 다 지켜야한다는 것이다. 다형성을 지원하기 위한 원칙, 인터페이스로 구현한 구현체를 믿고 사용하려면 이 원칙이 필요하다.
- 객체 지향 설계를 위해서 기능을 구현한 인터페이스의 신뢰가 필요하다. 그렇기에 단순히 컴파일에 성공 하는 것을 넘어서 해당 인스턴스 설계 의도대로 움직이고 있는지를 확인하는 LSP 원칙을 잘 지키고 있는지 확인할 필요가 있다.
- 다형성에서 하위 클래스는 인터페이스 규약을 다 지켜야 한다는 것, 다형성을 지원하기 위한 원칙, 인터페이스를 구현한 구현체를 믿고 사용하려면
-
DIP - 의존관계 역전 원칙
- 추상화에 의존해야지, 구체화에 의존하면 안된다. 클라이언트는 인터페이스만 바라봐야지 구현체는몰라야 한다. 구현체에 의존하지말고 인터
spring sercurity
-
UsernamePasswordAuthenticationFilter 등록
- attemptAuthentication() 함수를 오버라이딩하고 아래와 같이 구현한다.
- request의 username과 password를 ObjectMapper로 받는다. (파싱해서 java Object로 받기)
- 해당 username과 password로 UsernamePasswordAuthenticationToken을 생성한다.
- UsernamePasswordAuthenticationToken으로 Authentication 객체를 만든다.
- Authentication 객체를 만들 때 자동으로 UserDetailsService가 호출된다.
- 그렇기 때문에 UserDetailsService를 상속하여 직접 서비스를 구현한다.
- UserDetailsService를 통해서 리턴될 UserDetails를 커스텀해서 구현한다.
-
AuthenticationProvider 관련 팁
- authenticate() 함수가 호출되면 인증 프로바이더가 UserDetailsService의 loadUserByUsername(토큰의 첫번째 파라미터)를 호출하고
- UserDetails를 리턴받아서 토큰의 두 번째 파라미터(credential)과 UserDetails(DB값)의 getPassword()함수로 비교해서
- 동일하면 Authentication 객체를 만들어서 필터체인으로 리턴해준다.
- tip: 인증 프로바이더의 디폴트 서비스는 UserDetailsService 타입
- tip : 인증 프로바이더의 디폴트 암호화 방식은 BCryptPasswordEncoder
- 결론은 인증 프로바이더에게 알려줄 필요가 없음
-
인가
- tip: JWT를 사용하면 UserDetailsService를 호출하지 않기 때문에 @AuthenticationPrincipal 사용 불가능하다. 왜냐하면 @AuthenticationPrincipal은 UserDetailsService에서 리턴될 때 만들어 지기 때문이다.
- tip: 토큰 검증(이게 인증이기 때문에 AuthenticationManager도 필요없음)
- tip: 스프링 시큐리티가 수행해주는 권한처리를 위해 아래와 같이 토큰을 만들어서 Authentication 객체를 강제로 만들고 그걸 세션에 저장! ⇒ 나중에 컨트롤러에서 DI해서 쓸 때 편하다.
JWT
-
JWT 기반 authentication 기능에서 JWT의 secret key 암호화 알고리즘으로 HMAC SHA512를 사용함
-
MAC (Message Authentication Code)
- 메세지의 무결성과 메세지 인증 목적으로 사용
- 사용자 간 공유된 key를 가지고 메세지 해쉬값(MAC)을 생성하여, 메세지가 내가 원하는 사용자로부터 왔는지 판단
-
HMAC (Keyed-Hashed Message Authentication Code)
- 해시 함수를 이용해서 메시지 인증 코드를 구성하는 것을 HMAC이라고 한다.
- 원본 메시지가 변하면 그 해시값도 변하는 해싱(Hashing)의 특징을 활용하여 메시지의 변조 여부를 확인하여 무결성과 기밀성을 제공.
- HMAC은 인증을 위한 secret Key와 임의의 길이를 가진 Message를 해시 함수(알고리즘)을 사용해서 생성한다. 해시 함수로는 MD5, SHA-256과 같은 일반적인 해시 함수를 그대로 사용할 수 있으며 각 알고리즘에 따라 다른 고정길이의 MAC(Hash value)가 생성된다.
@Transational
https://mommoo.tistory.com/92#recentEntries
jpa의 객체 변경 감지는 transaction이 commit될 때, 작동합니다. 그렇기에 spring은 @transational 어노테이션을 선언한 메서드가 실행 되기 전 => transaction begin 코드를 삽입하고 메서드가 실행된 후 => transation commit 코드를 삽입하여, 객체 변경 감지를 수행하게 유도합니다.
Spring의 코드 삽입 방법은 크게 2가지 방법이 있습니다.
- 바이트 코드 생성 2. 프록시 객체 사용 이 중 스프링은 기본적으로 프록시 객체 사용이 선택됩니다. 그렇기에 interface가 반드시 필요합니다. springboot는 기본적으로 바이트 코드 생성이 선택됩니다. 그렇기에, 굳이 interface가 필요없습니다. 만약 개발환경이 springboot 라면 books 인터페이스 없이 봐도 무방합니다.
JAVA Reflection ?
generic
소켓(soket)
https://helloworld-88.tistory.com/215
소켓은 프로세스가 드넓은 네트워크 세계로 데이터를 내보내거나 혹은 그 세계로부터 데이터를 받기 위한 실제적인 창구 역할을 한다. 그러므로 프로세스가 데이터를 내보내거나 받기 위해서는 반드시 소켓을 열어서 소켓에 데이터를 써보내거나 소켓으로부터 데이터를 읽어들여야 한다. 소켓은 프로토콜, IP주소, 포트 넘버로 정의된다.
- 프로토콜 : 어떤 시스템이 다른 시스템과 통신을 원활하게 수용하도록 해주는 통신 규약, 약속
- IP : 전 세계 컴퓨터에 부여된 고유의 식별 주소
- 포트 : 네트워크 상에서 통신하기 위해서 호스트 내부적으로 프로세스가 할당받아야 하는 고유한 숫자이다. 한 호스트 내에서 네트워크 통신을 하고 있는 프로세스를 식별하기 위해 사용되는 값이므로, 같은 호스트 내에서 서로 다른 프로세스가 같은 포트 넘버를 가질 수 없다. 즉, 같은 컴퓨터 내에서 프로그램을 식별하는 번호이다.
다시 말해 소켓은 떨어져 있는 두 호스트를 연결해주는 도구로써 인터페이스의 역할을 하는데 데이터를 주고 받을 수 있는 구조체로 소켓을 통해 데이터 통로가 만들어진다. 이러한 소켓은 역할에 따라 서버 소켓, 클라이언트 소켓으로 구분된다.

서버 (Server) 클라이언트 소켓의 연결 요청을 대기하고, 연결 요청이 오면 클라이언트 소켓을 생성하여 통신이 가능하게 한다.
- 소켓 함수를 이용하여 소켓을 생성
- bind() 함수로 ip와 port 번호를 설정하게 됩니다.
- listen() 함수로 클라이언트의 접근 요청에 수신 대기열을 만들어 몇 개의 클라이언트를 대기 시킬지 결정
- accept() 함수를 사용하여 클라이언트와의 연결을 기다림
클라이언트(client) 실제로 데이터 송수신이 일어나는 것은 클라이언트 소켓이다.
- socket() 함수로 가장 먼저 소켓을 연다.
- connect() 함수를 이용하여 통신 할 서버의 설정된 ip와 port 번호에 통신을 시도
- 통신을 시도 시, 서버가 accept()함수를 이용하여 클라이언트의 socket descriptor를 반환
- 이를 통해 클라이언트와 서버가 서로 read(), write()를 하며 통신 (이 과정이 반복)
소켓 종류 스트림(TCP)
- 양방향으로 바이트 스트림을 전송, 연결 지향성
- 오류 수정, 전송처리, 흐름제어 보장
- 송신된 순서에 따라 중복되지 않게 데이터를 수신 → 오버헤드가 발생
- 소량의 데이터보다 대량의 데이터 전송에 적합 → TCP를 사용 데이터그램 (TCP)
- 비연결형 소켓
- 데이터의 크기에 제한이 있음
- 확실하게 전달이 보장되지 않음, 데이터가 손실돼도 오류가 발생하지 않음
- 실시간 멀티미디어 정보를 처리하기 위해 주로 사용 ex) 전
HTTP통신과 SOCKET 통신의 비교
-
HTTP 통신
-
Client의 요청이 있을 때만 서버가 응답하여 해당 정보를 전송하고 곧바로 연결을 종료하는 방식
-
HTTP 통신의 특징
-
Client가 요청을 보내는 경우에만 server가 응답하는 단방향 통신이다.
-
server로부터 응답을 받은 후에는 연결이 바로 종료된다.
-
실시간 연결이 아니고, 필요한 경우에만 server로 요청을 보내는 상황에 유용하다.
-
요청을 보내 server의 응답을 기다리는 어플리케이션의 개발에 주로 사용된다.
-
SOCKET 통신
-
Server와 Client가 특정 port를 통해 실시간으로 양방향 통신을 하는 방식
-
SOCKET 통신의 특징
-
Server와 Client가 계속 연결을 유지하는 양방향 통신이다.
-
Server와 Client가 실시간으로 데이터를 주고받는 상황이 필요한 경우에 사용된다.
-
실시간 동영상 streaming이나 온라인 게임등과 같은 경우에 자주 사용된다.
TCP 송/수신 원리
https://www.youtube.com/watch?v=K9L9YZhEjC0
소켓의 본질은 파일 process가 file에 할 수 있는 operation은 RWX → 소켓 통신에서 Read는 Receive, Write는 Send
네트워크와 인터넷 기본 개념, ISP
네트워크 : 컴퓨터나 기타 기기들이 리소스를 공유하거나 데이터를 주고 받기 위해 유선 혹은 무선으로 연결된 통신 체계
LAN (local area network)
- Ethernet 유선 통신
- wireless Lan == wifi 무선 통신
WAN (wide area network)
- 여러 LAN이나 다른 종류의 네트워크들을 하나로 묶어서 멀리 떨어진 기기들도 통신이 가능하도록 만든 네트워크
- 훨씬 더 넓은 범위를 커버하는 네트워크 e.g.) 은행의 atm, wireless WAN(4G, 5G), Internet
Internet
- the network of networks
- the world's largest WAN
- global network
ISP (internet service provider)
일반사용자나 회사, 기관 등이 인터넷을 사용할 수 있도록 인터넷 연결 서비스를 제공하는 존재 역할과 규모에 따라 tier가 나뉜다. tier 1 : 국제 범위의 네트워크 보유, 인터넷의 모든 네트워크 접근 가능, 인터넷의 중추 역할(backbone) tier 2 : 국가 / 지방 범위 네트워크 보유, 일반 사용자나 기업 대상 서비스, 인터넷의 모든 영역에 연결되기 위해 tier 1 ISP에 비용을 내고 트래픽 전송 tier 3 : 작은 지역 범위 서비스 제공, 일반 사용자나 기업 대상 서비스, 상위 ISPs에게 비용을 내고 인터넷 트래픽을 구매해서 이를 통해 서비스
라우터
목적하는 네트워크에 데이터를 보내는 장치 서로 다른 ISP가 관리하는 네트워크를 연결시켜주는 역할
end system, 호스트(host)
- 네트워크의 끝에 있는 노드
- 네트워크를 사용하기 위해 연결된 노드
- 클라이언트와 서버로 나뉨
https://www.youtube.com/watch?v=oFKYzp6gGfc&list=PLcXyemr8ZeoSGlzhlw4gmpNGicIL4kMcX&index=1
프로토콜과 OSI 7 layer
네트워크 프로토콜(network protocol) : 네트워크 통신을 하기 위해서 통신에 참여하는 주체들이 따라야 하는 형식, 절차, 규약
layered architecture
- OSI model (7 layer) : 범용적인 네트워크 구조
- TCP/IP stack (4 layer) : 인터넷에 특화된 네트워크 구조
OSI 7 layer
- 각 레이어에 맞게 프로토콜이 세분화되서 구현
- 각 레이어의 포로토콜은 하위 레이어의 포로토콜이 제공하는 기능을 사용하여 동작

- application layer
- 애플리케이션 목적에 맞는 통신 방법 제공
- HTTP, DNS, SMTP, FTP
- presentation layer
- 애플리케이션 간의 통신에서 메세지 포맷 관리
- 인코딩 ↔ 디코딩
- 암호화 ↔ 복호화
- 압축 ↔ 압축 풀기
- session layer
- 애플리케이션 간의 통신에서 세션을 관리
- RPC (remote procedure call)
- 여기까지 application layer
- transport layer
- 애플리케이션 간의 통신 담당
- 목적지 애플리케이션으로 데이터 전송
- 안정적이고 신뢰할 수 있는 데이터 전송 보장(TCP)
- 필수 기능만 제공(UDP)
- 목적지까지 어떤 식의 통신을 할 것인가를 결정하는 레이어
- not 실제로 보낼려는 데이터가 어떻게 목적지까지 찾아가게 하는지는 관심사가 아님. 해당 기능을 networt layer가 담당하는 기능이고 transport layer는 그 기능을 사용해서 실제로 어떤 방식으로 application까지 데이터를 전달할 것이냐를 구현하고 담당하는 레이어다.
- network layer
- data link layer
- 직접 연결된 노드 간의 통신 담당
- MAC 주소 기반 통신 (ARP)
- IP주소를 MAC기반으로 변환해야 하는데 이때 사용하는 프로토콜이 ARP 프로토콜이다. MAC주소를 바탕으로 다음 노드로 데이터를 전송할 수 있음.
- physical layer

https://www.youtube.com/watch?v=6l7xP7AnB64&list=PLcXyemr8ZeoSGlzhlw4gmpNGicIL4kMcX&index=2